Verbal Autopsy 텍스트 분류를 위한 머신러닝 방법 비교 연구
초록
본 연구는 사망 원인 추정을 위한 Verbal Autopsy(VA) 텍스트를 자동으로 분류하기 위해, 다양한 특성 표현 방식과 머신러닝 알고리즘을 비교한다. 정규화된 단어 빈도와 TF‑IDF가 비슷한 성능을 보였으며, 지원 벡터 머신(SVM)이 가장 우수했다. 또한 “지역‑반지도학습” 기반의 특성 축소 기법이 정확도를 현저히 향상시켰다.
상세 분석
본 논문은 개발도상국에서 흔히 발생하는 사망 원인 미확인 사례를 다루는 Verbal Autopsy(VA) 텍스트를 자동 분류하는 문제에 초점을 맞추었다. VA는 현장 조사원이 사망자 친척과 인터뷰한 기록이며, 비정형 자연어 형태로 저장된다. 이러한 텍스트는 어휘가 매우 다양하고, 오탈자와 비표준 표현이 다수 포함돼 전통적인 의료 코딩 시스템에 바로 적용하기 어렵다. 따라서 텍스트 분류 기법을 적용하기 전에 적절한 특성 표현과 차원 축소가 필수적이다.
연구자는 먼저 1,200건 이상의 VA 문서를 5개의 사망 원인 카테고리(예: 감염성 질환, 비감염성 질환, 외상, 산과·출산 관련, 기타)로 라벨링하였다. 전처리 단계에서는 토큰화, 소문자 변환, 불용어 제거(영어와 현지 언어 혼합) 등을 수행했으며, 어간 추출보다는 원형 보존을 선택해 의미 손실을 최소화하였다.
특성 표현은 네 가지 방식으로 실험되었다. (1) 이진 존재/부재(Binary), (2) 단어 빈도(Term Frequency, TF), (3) 정규화된 TF(Normalized TF, 문서 길이로 나눔), (4) TF‑IDF. 정규화된 TF와 TF‑IDF는 희소성을 보정하면서도 중요한 단어에 가중치를 부여한다는 점에서 차이가 있었다.
분류 알고리즘으로는 나이브 베이즈(Naïve Bayes), 서포트 벡터 머신(SVM, 선형 커널), 랜덤 포레스트(Random Forest), 그리고 k‑최근접 이웃(k‑NN)을 적용하였다. 각 모델은 10‑폴드 교차 검증을 통해 정확도, 매크로 F1 점수, 그리고 ROC‑AUC를 평가하였다. 결과는 SVM이 모든 특성 표현에서 가장 높은 정확도(≈78 %)와 매크로 F1(≈0.71)을 기록했으며, 특히 정규화된 TF와 TF‑IDF에서 차이가 미미함을 보여준다. 나이브 베이즈는 빠른 학습 속도에도 불구하고 정확도가 10 % 수준에서 낮았고, 랜덤 포레스트와 k‑NN은 차원 저주와 클래스 불균형으로 인해 성능이 제한적이었다.
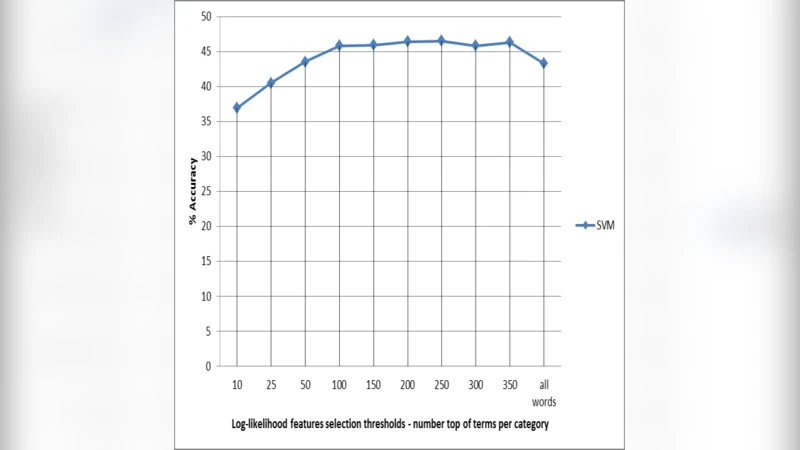
특성 축소 전략으로는 “지역‑반지도학습(locally‑semi‑supervised)” 접근을 채택했다. 구체적으로 각 클래스별로 로그우도비(Likelihood Ratio) 통계량을 계산해 상위 200개의 단어를 선택하고, 이를 전체 특성 집합에 병합하였다. 이 방법은 전통적인 차원 축소(PCA, χ²)보다 간단하면서도 클래스 특이성을 유지한다. 실험 결과, SVM에 이 축소된 특성을 적용했을 때 정확도가 3‑4 % 상승했으며, 모델 학습 시간도 크게 단축되었다.
전체적으로 본 연구는 VA 텍스트 분류에 있어 (1) 정규화된 TF와 TF‑IDF가 효과적이며, (2) 선형 SVM이 가장 강력한 분류기임을, (3) 클래스별 로그우도비 기반의 지역‑반지도학습 특성 축소가 성능과 효율성을 동시에 개선한다는 점을 입증한다. 또한, 데이터 불균형 문제와 현지 언어 혼합 특성 때문에 향후 연구에서는 비용 민감 학습, 앙상블 기법, 그리고 심층 학습 기반의 사전학습 언어 모델 적용이 필요함을 시사한다.