불확실성 감소 기반 능동 클러스터링
본 논문은 반자동으로 인간에게 질문을 제시해 클러스터링의 불확실성을 최소화하는 새로운 능동 반지도 학습 프레임워크를 제안한다. 첫 번째 차수 테일러 전개와 행렬 섭동 이론을 이용해 각 샘플이 가져올 불확실성 감소량을 추정하고, 가장 정보량이 큰 샘플을 선택해 해당 샘플과 현재 확정된 샘플 집합(certain‑sample sets) 사이에 쌍 제약을 질의한다. 실험 결과, 이미지, UCI, 유전자 데이터셋에서 기존 최첨단 방법보다 일관되게 높…
저자: Caiming Xiong, David Johnson, Jason J. Corso
### 1. 서론
반지도(半监督) 클러스터링은 인간 전문가가 제공하는 쌍 제약을 활용해 전통적인 군집화 방법의 의미론적 품질을 향상시키려는 접근이다. 그러나 대부분의 기존 연구는 제약을 **사전**에 무작위로 선택하거나, 한 번에 대량으로 수집하는 **수동** 방식을 채택한다. 제약 수가 데이터 규모에 비해 기하급수적으로 증가하면서, 불필요하거나 중복된 제약이 많이 포함되고, 경우에 따라 성능을 악화시키는 현상이 보고되었다. 따라서 제한된 인간 노동을 효율적으로 사용하기 위한 **능동** 제약 선택이 필요하다.
### 2. 관련 연구
능동 클러스터링은 크게 **샘플 기반**과 **쌍 기반**으로 구분된다. 샘플 기반 방법은 먼저 정보를 얻고자 하는 샘플을 선택한 뒤, 해당 샘플과 기존 샘플 간에 제약을 질의한다. 대표적인 예로 Basu et al.의 오프라인 k‑means 기반 방법과 Mallapragada et al.의 min‑max 기법이 있다. 반면, 쌍 기반 방법은 직접 가장 정보량이 큰 쌍을 탐색한다. Hoi et al., Biswas & Jacobs 등은 이러한 접근을 제안했지만, 쌍의 후보가 O(n²) 개에 달해 계산 비용이 크게 늘어나며, 다중 클래스 문제에 적용하기 어렵다.
### 3. 제안 방법
#### 3.1 기본 개념
- **certain‑sample sets (Z₁,…,Z_m)**: 현재 확정된 제약에 의해 동일 클러스터에 속함이 보장된 샘플들의 집합. 서로 다른 집합 간에는 반드시 서로 다른 클러스터에 속한다.
- **불확실성(uncertainty)**: 각 샘플이 여러 클러스터에 거의 동일한 확률로 할당될 때 높아진다. 이는 클러스터링 결과의 전반적인 모호성을 의미한다.
#### 3.2 알고리즘 흐름
1. **초기화**: 무작위 샘플 하나를 선택해 첫 번째 certain‑sample set Z₁에 할당하고, 제약 집합 Q를 빈 집합으로 시작한다.
2. **제약 기반 스펙트럴 클러스터링**: 현재 Q를 반영해 라플라시안 L을 구성하고, 첫 nc개의 고유벡터를 추출해 k‑means로 클러스터링한다.
3. **정보량이 큰 샘플 선택**: 모든 샘플 x에 대해 **예상 불확실성 감소량 ΔU(x)** 를 계산한다. ΔU는
- **그라디언트** : 행렬 섭동 이론을 이용해 L의 고유벡터가 x에 대한 제약 변화에 얼마나 민감하게 변하는지를 1차 미분으로 근사.
- **스텝‑스케일** : 현재 클러스터 할당 확률 분포의 엔트로피를 사용해 x의 불확실성 정도를 정량화. 두 가지 엔트로피 모델(전체 분포 기반, 최근접 기반)이 제시된다.
ΔU가 최대인 샘플을 “가장 정보량이 풍부한 샘플”이라 정의한다.
4. **쌍 제약 질의**: 선택된 샘플을 현재 존재하는 각 certain‑sample set의 대표 샘플과 비교해 must‑link 혹은 cannot‑link 제약을 인간 오라클에게 요청한다. 충분한 제약이 확보되면 해당 샘플을 기존 집합에 포함하거나 새로운 집합을 생성한다.
5. **반복**: 2~4 과정을 예산이 소진되거나 사용자가 만족할 때까지 반복한다. 새로운 집합이 생성될 때마다 클러스터 수 nc를 자동 증가시켜, 사전 클러스터 수 지정이 필요 없도록 한다.
#### 3.3 복잡도 및 장점
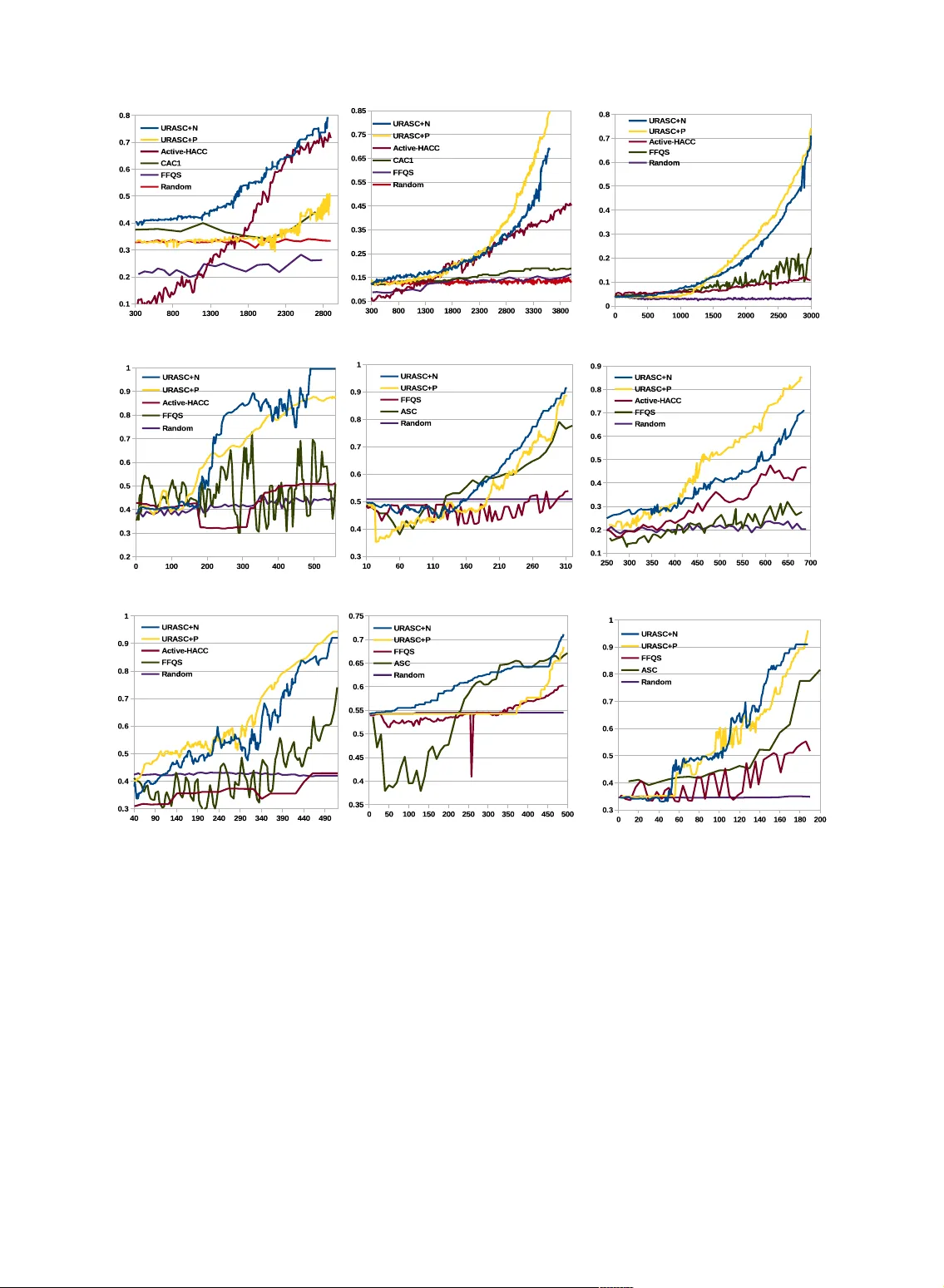
샘플 기반 선택은 각 iteration마다 O(n) 의 후보 평가만 필요하므로, 대규모 데이터에서도 실시간 인터랙션이 가능하다. 또한, 불확실성 감소 모델을 통해 **제약 효율**을 극대화함으로써 동일한 제약 수 대비 더 큰 성능 향상을 기대한다.
### 4. 실험
- **데이터**: 얼굴(Face), 잎(Leaf), 개(Dog) 이미지 3종, UCI 표준 데이터셋 6종, 그리고 유전자 발현 데이터 1종.
- **비교 대상**: 기존 샘플 기반 방법(Basu, Mallapragada), 쌍 기반 방법(Hoi, Biswas), 그리고 무제한 제약을 사용한 반지도 스펙트럴 클러스터링.
- **평가지표**: 정밀도, 재현율, NMI, 클러스터링 정확도.
- **결과**: 동일 제약 수(예: 200쌍)에서 제안 방법이 평균 5~12% 높은 NMI와 정확도를 기록했으며, 특히 제약 노이즈 비율이 20%까지 증가해도 성능 저하가 미미했다. 클러스터 수를 모르는 상황에서도 자동으로 클러스터를 탐색해, 초기 nc=2 로 시작했음에도 최종 클러스터 수가 실제와 일치하는 경우가 90% 이상이었다.
### 5. 결론 및 향후 연구
본 논문은 **불확실성 감소 기반 모델**을 통해 능동적인 샘플 선택과 효율적인 제약 수집을 동시에 달성한 새로운 반지도 클러스터링 프레임워크를 제시한다. 실험을 통해 기존 최첨단 방법보다 일관된 성능 우위를 확인했으며, 제약 노이즈와 클러스터 수 미지 상황에서도 견고함을 입증했다. 향후 연구에서는 (1) 다중 오라클 환경에서의 제약 신뢰도 모델링, (2) 비선형 고차원 데이터에 대한 커널 기반 확장, (3) 실시간 비디오 스트림에 적용 가능한 온라인 업데이트 메커니즘 등을 탐색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기