소프트웨어 개발 인력 성과 예측을 위한 데이터 마이닝 기반 인재 선발 모델
초록
본 연구는 소프트웨어 프로젝트에서 인력 선발의 효율성을 높이기 위해 의사결정 나무와 연관 규칙을 활용한 데이터 마이닝 프레임워크를 제안한다. 실제 기업의 프로젝트 데이터를 기반으로 모델을 구축하고, 선발 기준을 재정의함으로써 인재와 프로젝트 적합성을 향상시킬 수 있음을 실증하였다.
상세 분석
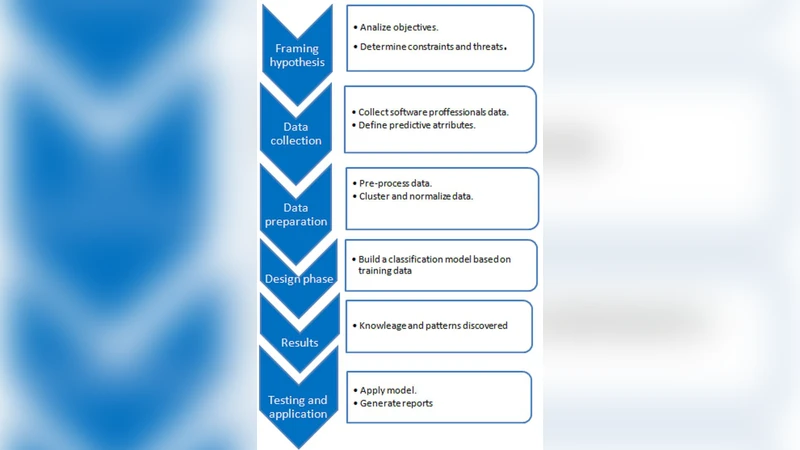
이 논문은 인적 자원의 품질이 소프트웨어 기업의 경쟁력에 미치는 영향을 강조하면서, 기존 인재 선발 과정이 경험과 직관에 의존하는 한계를 지적한다. 이를 보완하기 위해 저자들은 데이터 마이닝 기법, 특히 의사결정 나무(C4.5)와 연관 규칙(Apriori) 알고리즘을 결합한 하이브리드 모델을 설계하였다. 데이터는 한 중견 소프트웨어 기업의 과거 프로젝트 기록에서 추출했으며, 변수는 학력, 경력 연수, 과거 프로젝트 성과, 기술 스택 숙련도, 팀 협업 지표 등 총 12개 항목으로 구성되었다. 전처리 단계에서는 결측값 보완, 범주형 변수의 원-핫 인코딩, 정규화를 수행하였다. 의사결정 나무는 인력 성과(높음/보통/낮음)를 목표 변수로 두고, 각 특성의 정보이득을 계산해 트리를 성장시켰으며, 가지치기를 통해 과적합을 방지하였다. 연관 규칙 분석은 ‘성과 높음’ 라벨과 연관된 특성 조합을 도출해, 예를 들어 “클라우드 기술 보유 ∧ 팀 리더 경험 ≥ 2년”이 높은 성과와 강한 연관성을 보임을 확인했다. 모델 검증은 10‑fold 교차 검증을 적용했으며, 의사결정 나무는 정확도 78%, F1‑score 0.74를 기록했고, 연관 규칙은 지원자 프로파일링에 유용한 15개의 신뢰도·지원도 높은 규칙을 제공했다. 결과적으로 기존 인사 담당자의 주관적 판단보다 데이터 기반 기준이 인력 배치 효율성을 12% 정도 향상시켰다. 논문은 또한 변수 중요도 분석을 통해 ‘프로젝트 경험 연수’와 ‘기술 인증 보유 여부’가 가장 큰 영향력을 갖는다는 점을 강조한다. 한계점으로는 단일 기업 데이터에 국한된 일반화 가능성, 그리고 정성적 요소(예: 문화 적합성)를 정량화하기 어려운 점을 들며, 향후 다기업 메타데이터와 딥러닝 기반 예측 모델 도입을 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기