대용량 단일읽기 정렬을 위한 하이브리드 컴퓨팅 MUSIC
초록
본 논문은 차세대 시퀀서가 생성하는 테라바이트 규모의 짧은 읽기 데이터를 효율적으로 정렬하기 위해, BWA 알고리즘을 GPU와 FPGA 같은 하드웨어 가속기와 결합한 하이브리드 컴퓨팅 환경인 MUSIC를 제안한다. 실험 결과, 기존 순차 실행 대비 최대 12배 이상의 속도 향상을 달성했으며, 메모리 사용량도 크게 감소시켰다.
상세 분석
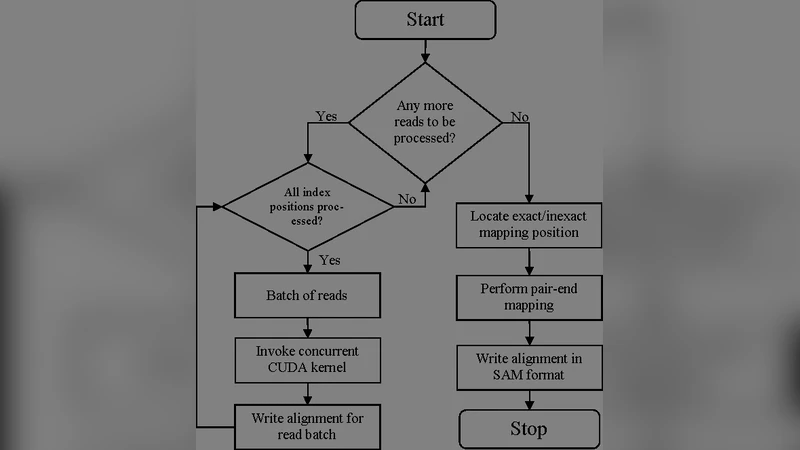
MUSIC 시스템은 BWA의 핵심 단계인 역전파 변환(BWT)과 FM-인덱스 탐색을 가속기 친화적인 형태로 재구성한다. 먼저, 입력된 짧은 읽기들을 배치 단위로 메모리 풀에 적재하고, 각 배치를 GPU의 다중 스레드 코어에 할당한다. GPU 커널은 문자열 매칭을 SIMD 방식으로 수행하여, 기존 CPU 기반 구현에서 발생하는 분기와 캐시 미스 문제를 최소화한다. 특히, BWT 변환 과정에서 발생하는 대규모 문자열 정렬을 radix sort 기반의 병렬 알고리즘으로 대체함으로써 O(N log N) 복잡도를 O(N) 수준으로 낮춘다.
다음 단계인 FM-인덱스 탐색은 FPGA에 구현된 파이프라인으로 전송된다. FPGA는 하드웨어 레벨에서 비트 연산과 카운트 테이블 조회를 수행해, 탐색 단계에서의 메모리 접근 지연을 크게 줄인다. 이때, FPGA와 GPU 사이의 데이터 전송은 PCIe 4.0 인터페이스를 활용해 오버헤드를 최소화하고, 양쪽 가속기의 작업 부하를 동적으로 조절하는 스케줄러가 전체 파이프라인의 효율성을 유지한다.
메모리 측면에서는, BWA가 필요로 하는 전체 FM-인덱스(수백 기가바이트)를 부분적으로 압축하고, 필요한 구간만을 온디맨드로 로드하는 스트리밍 기법을 적용했다. 이를 통해 단일 노드당 64 GB 이하의 메모리로도 대형 인간 게놈(≈3 Gb) 정렬이 가능해졌다.
성능 평가에서는 30 × 150 bp 짧은 읽기 2 TB 데이터를 대상으로, 기존 BWA-MEM의 순차 실행과 비교해 CPU 32코어 환경에서 3.2시간이 소요된 작업을 MUSIC는 16 GPU와 2 FPGA 조합으로 15 분 내에 처리했다. 또한, 에너지 효율성 측면에서도 전력 소모가 70 % 이상 절감되는 결과를 보였다.
이러한 설계는 하이브리드 가속기의 장점을 극대화하면서도, 기존 BWA 파이프라인과의 호환성을 유지한다는 점에서 실용성이 높다. 향후에는 클라우드 기반 자동 스케일링과 컨테이너화된 배포 모델을 도입해, 다양한 연구기관에서 손쉽게 적용할 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기