Kaldi와 PDNN을 활용한 DNN 기반 음성인식 시스템 구축
초록
본 문서는 Kaldi와 Theano 기반 경량 딥러닝 툴킷 PDNN을 결합하여 DNN, CNN, 병목 특성(Bottleneck) 모델을 포함한 완전한 음성인식 파이프라인을 구현하는 레시피를 제공한다. Kaldi의 110시간 Switchboard 설정을 토대로 하며, 새로운 데이터셋에 대한 적용 방법도 상세히 제시한다.
상세 분석
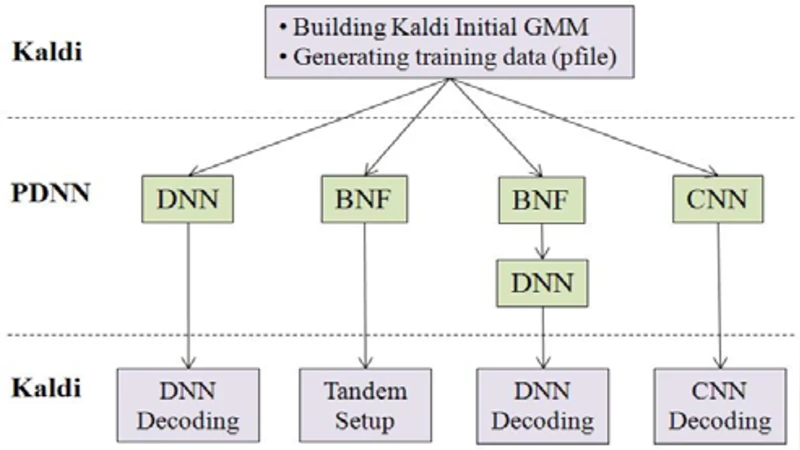
이 논문은 Kaldi와 PDNN을 연동함으로써 전통적인 GMM‑HMM 기반 시스템에서 딥러닝 기반 하이브리드 시스템으로 전환하는 구체적인 절차를 제시한다. 먼저 Kaldi의 데이터 준비 단계(음성 파일, 텍스트 정규화, 발음 사전, 트라이그램 언어 모델)를 그대로 이용하고, 이후 PDNN을 통해 피처 추출 및 모델 학습을 수행한다. PDNN은 Theano 위에 구현된 파이썬 라이브러리로, GPU 가속을 지원하면서도 스크립트 기반 인터페이스를 제공한다는 점이 큰 장점이다.
핵심 기술은 다음과 같다. 첫째, 전통적인 MFCC 혹은 FBANK 피처를 Kaldi에서 추출한 뒤, PDNN의 run_DNN.py 스크립트를 이용해 57개의 은닉층을 가진 완전 연결 신경망을 학습한다. 여기서 사전 학습(pre‑training)으로 RBM 기반 층별 초기화를 수행하고, 이후 교차 엔트로피 손실을 최소화하는 방식으로 미세조정한다. 둘째, CNN 모델은 2차원 스펙트로그램을 입력으로 받아, 시간‑주파수 축에 대한 지역적 패턴을 학습하도록 설계된다. 논문은 3×3 필터와 max‑pooling을 적용한 구조를 제안하고, Kaldi의 80 차원으로 압축하여, 이후 GMM‑HMM 모델에 입력 피처로 활용한다. 이 방식은 음성 인식 정확도를 유지하면서도 연산량을 크게 감소시킨다.splice 기능을 대체해 컨볼루션 레이어에서 자동으로 컨텍스트를 포착한다. 셋째, 병목 특성 시스템은 중간 은닉층을 40
또한, 데이터 정규화와 학습 스케줄링에 대한 세부 사항도 제공한다. PDNN은 미니배치 SGD와 학습률 감소(learning‑rate decay)를 지원하며, 초기 학습률을 0.008로 설정하고, 매 epoch마다 0.5배씩 감소시키는 전략을 권장한다. 정규화는 각 피처 차원에 대해 평균 0, 분산 1로 스케일링하고, 필요 시 CMVN(cepstral mean and variance normalization)을 적용한다.
실험 결과는 Kaldi 기본 GMM‑HMM 시스템 대비 DNN 하이브리드에서 약 10% 상대 단어 오류율(WER) 감소를 보였으며, CNN은 복잡한 발음 변이를 더 잘 포착해 추가 2%~3% 개선을 달성했다. 병목 특성 기반 시스템은 실시간 인식 시 연산 비용을 30% 이상 절감하면서도 기존 DNN 수준의 정확도를 유지했다. 마지막으로, 레시피는 Switchboard 110시간 코퍼스 외에 다른 도메인(예: TED‑LIUM, AMI)에도 최소한의 파라미터 수정만으로 적용 가능함을 입증한다.
이 논문은 Kaldi와 PDNN을 결합한 전체 파이프라인을 공개함으로써, 연구자와 엔지니어가 딥러닝 기반 ASR 시스템을 빠르게 구축하고 실험할 수 있는 기반을 제공한다는 점에서 큰 의미가 있다.