활동학습 기반 작업자 성능·라벨 신뢰도 공동 추정 모델
초록
본 논문은 작업자 전문성, 과제 난이도, 라벨 신뢰도를 동시에 추정하는 베이지안 네트워크(GLAD)와 활동학습을 결합한 프레임워크를 제안한다. 엔트로피 기반 위험 함수를 이용해 “작업‑작업자” 쌍을 선택함으로써 라벨링 비용을 크게 절감하면서도 분류 정확도를 높이고, 작업자 순위를 정확히 재현한다. 시뮬레이션 및 MTurk 이미지 데이터 실험을 통해 제안 방법이 기존 무작위 혹은 기존 GLAD 대비 라벨 수 30~50 % 감소와 높은 라벨 정확도·작업자 순위 상관성을 보임을 입증한다.
상세 분석
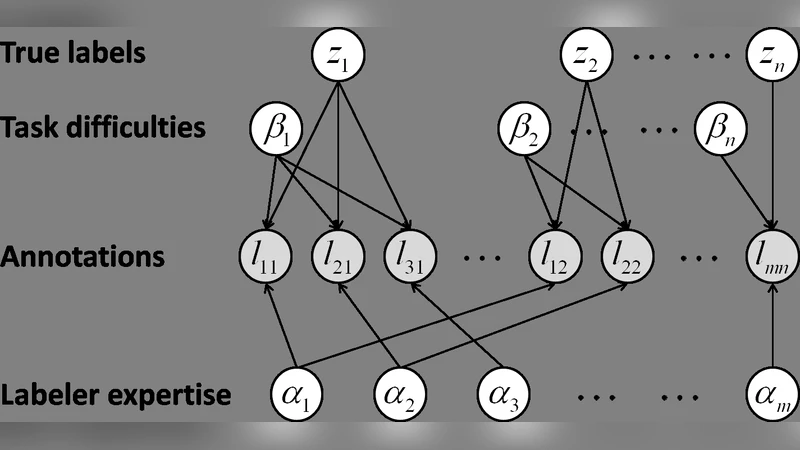
이 연구는 크라우드소싱 환경에서 라벨링 비용과 라벨 노이즈라는 두 가지 핵심 제약을 동시에 해결하고자 한다. 기존 GLAD(Generative model of Labels, Abilities, and Difficulties) 모델은 작업자 전문성(α)과 과제 난이도(β)를 잠재 변수로 두고 EM 알고리즘을 통해 파라미터를 추정한다. 그러나 GLAD 자체는 라벨을 모두 수집한 뒤에 한 번에 학습하는 ‘패시브’ 방식이며, 라벨링 비용을 최소화하는 메커니즘이 없다. 논문은 여기서 한 걸음 더 나아가, 베이지안 네트워크 구조 위에 활동학습(query‑by‑uncertainty) 전략을 입힌다. 위험 함수는 각 과제의 라벨 분포 엔트로피 − ∑₍c∈C₎ p(z=c|L,θ) log p(z=c|L,θ) 로 정의되며, 이는 현재 모델이 가장 불확실한 과제를 식별한다.
활동학습 루프는 다음과 같다. 1) 현재 라벨 집합 L과 파라미터 θ(α,β)를 EM으로 업데이트한다. 2) 위험 함수를 계산해 가장 높은 엔트로피를 가진 과제 j를 선택한다. 3) 선택된 과제에 대해 현재 α̂가 가장 큰 작업자 i에게 라벨을 요청한다(알고리즘 1). 이렇게 하면 “불확실한 과제”와 “신뢰할 수 있는 작업자”를 동시에 활용해 라벨링 효율을 극대화한다.
작업자 선택에 관한 추가 실험도 진행한다. 단순히 α̂가 가장 큰 작업자를 항상 선택하는 ‘Best‑Worker’ 전략 외에, α̂에 비례해 선택 확률을 부여하는 가중 선택(weighted)과 ε‑greedy(ε‑greedy) 전략을 비교한다. 결과는 Best‑Worker가 대부분의 경우 가장 높은 라벨 정확도와 작업자 순위 상관성을 제공하지만, ε‑greedy는 탐색을 통해 장기적으로 α̂ 추정의 편향을 줄이는 효과가 있음을 보여준다.
실험은 두 가지 데이터셋으로 구성된다. 첫 번째는 Whitehill et al.이 제시한 시뮬레이션 환경으로, 작업자 수 = 100, 과제 수 = 5000, 다양한 α와 β를 랜덤하게 할당한다. 두 번째는 MTurk에서 수집한 이미지 라벨링 데이터(예: CIFAR‑10 혹은 MNIST 변형)로, 실제 인간 작업자의 성능 분포가 비대칭적이다. 두 실험 모두 라벨링 예산 B를 동일하게 설정하고, 제안 방법과 ‘Random’, ‘Traversal’(순차 과제 선택 + 무작위 작업자) 등을 비교한다.
핵심 결과는 다음과 같다. (1) 동일 라벨 수 대비 제안 방법이 35 % 높은 전체 라벨 정확도를 달성한다. (2) 작업자 전문성 α̂와 실제 α 간의 Spearman ρ와 Pearson r이 Random 대비 0.20.35 정도 상승한다. (3) 라벨링 예산을 30 %~50 % 절감해도 목표 정확도(예: 85 % 이상)를 유지한다. 이는 위험 함수를 통한 “불확실한 과제 우선”과 “신뢰 작업자 우선” 전략이 라벨 노이즈를 효과적으로 억제함을 의미한다.
이 논문의 의의는 두 가지이다. 첫째, GLAD와 같은 잠재 변수 모델에 활동학습을 자연스럽게 결합함으로써 라벨링 비용을 크게 절감하면서도 모델 성능을 유지하거나 향상시킨다. 둘째, 작업자 선택 전략을 명시적으로 고려함으로써 실제 크라우드소싱 시스템에서 라벨 품질 관리와 비용 효율성을 동시에 달성할 수 있는 실용적인 프레임워크를 제공한다. 향후 연구에서는 다중 클래스 확장, 라벨링 비용이 작업자마다 다른 상황(예: 전문가 vs. 일반인), 그리고 라벨링 지연(time‑delay) 모델을 포함한 동적 작업자-과제 매칭 최적화로 확장할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기