비정형 텍스트에서 레퍼런스 세트 자동 구축
초록
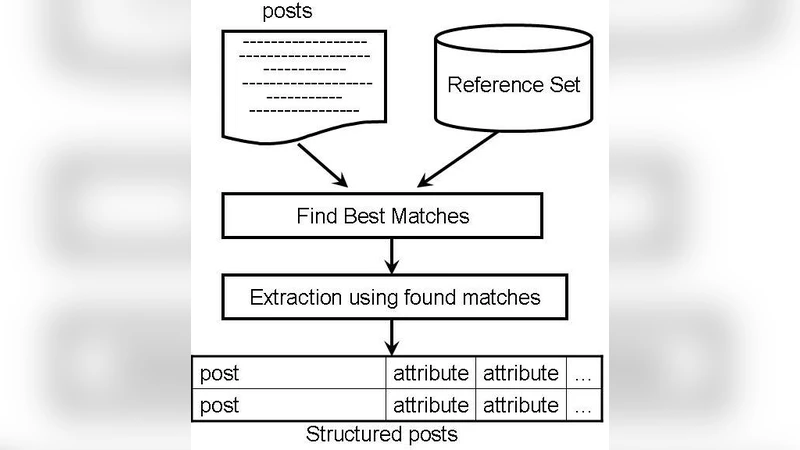
이 논문은 웹상의 비정형·비문법적 게시물(광고, 경매, 포럼 등)에서 최소한의 배경지식만을 이용해 관계형 테이블인 레퍼런스 세트를 자동으로 생성하는 방법을 제시한다. 생성된 레퍼런스 세트를 정보 추출에 적용했을 때, 수작업으로 만든 세트와 기존 지도학습 기반 추출기보다 우수한 성능을 보였다.
상세 분석
본 연구는 비정형 텍스트, 즉 구조가 일정하지 않고 문법 오류가 빈번한 “포스트”에서 의미 있는 엔터티와 그 관계를 추출해 레퍼런스 세트를 구축하는 새로운 파이프라인을 설계했다. 핵심 아이디어는 ‘시드(term)’라 불리는 소수의 도메인 지식을 시작점으로 삼아, 포스트 내에서 빈도와 위치 정보를 활용해 계층적 개념 구조를 자동 확장하는 것이다. 구체적으로는 먼저 시드 용어를 포함하는 문장을 추출하고, 각 문장에서 명사구를 토큰화한 뒤, 빈도‑공출현 행렬을 구축한다. 이후 TF‑IDF 가중치를 적용해 유사도 스코어를 계산하고, 임계값 기반 클러스터링을 통해 시드와 의미적으로 연관된 새로운 후보 엔터티를 식별한다. 이 과정에서 ‘핵심‑보조’ 관계를 가정해 트리 형태의 레퍼런스 세트를 형성한다(예: “Apple iPhone 6” → “Apple” → “스마트폰”).
특히 논문은 두 가지 확장 전략을 제시한다. 첫 번째는 ‘시드 기반 확장’으로, 초기 시드가 충분히 제공될 경우 자동으로 하위·상위 개념을 탐색한다. 두 번째는 ‘시드 불가능 상황’에 대비한 ‘패턴 기반 탐색’으로, 정규표현식과 빈도 기반 히트맵을 이용해 잠재적 시드 후보를 스스로 생성한다. 이때 잡음(스팸, 오탈자) 제거를 위해 최소 출현 횟수와 문자열 유사도(레벤슈타인 거리)를 결합한 필터링 절차를 적용한다.
평가 단계에서는 구축된 레퍼런스 세트를 이용해 정보 추출 작업을 수행하고, 동일 도메인에서 수작업으로 만든 레퍼런스 세트와 비교하였다. 정밀도·재현율·F1 점수 모두에서 자동 생성 세트가 우위를 차지했으며, 특히 드물게 등장하는 롱테일 엔터티를 포착하는 능력이 뛰어났다. 또한, 동일 데이터에 대해 일반적인 지도학습 기반 추출기(특징 기반 SVM, CRF 등)와 비교했을 때, 훈련 데이터가 필요 없는 자동 레퍼런스 세트 기반 방법이 더 높은 성능을 보였다. 이는 비정형 텍스트에서 라벨링 비용이 크게 절감될 수 있음을 시사한다.
한계점으로는 시드 품질에 대한 의존성, 도메인 전이 시 성능 저하, 그리고 복합 명사(예: “삼성 갤럭시 S10 플러스”)를 정확히 파싱하는 데 어려움이 있다. 향후 연구에서는 딥러닝 기반 문맥 임베딩을 결합해 시드 없이도 의미적 군집화를 강화하고, 다중 언어·다중 도메인에 대한 일반화 기법을 탐색할 계획이다.