데이터 충돌로 찾는 보편적 유사성 측정법
초록
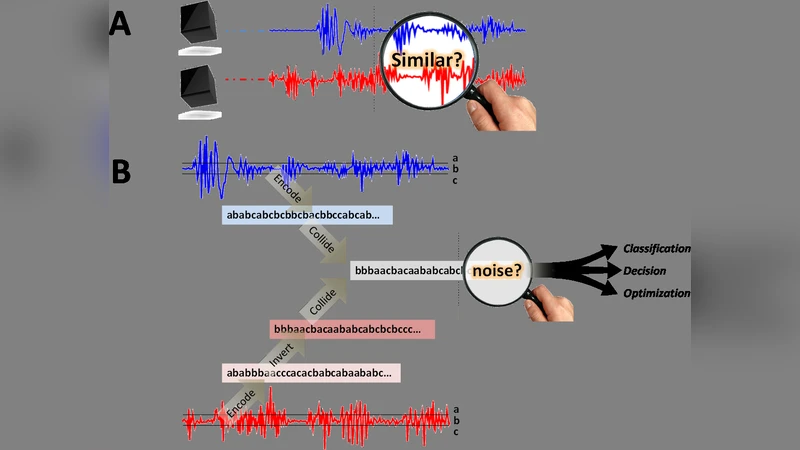
‘데이터 스매싱’은 연속 신호를 기호열로 양자화한 뒤, 각 스트림의 통계적 반대인 안티‑스트림을 생성하고 두 스트림을 합성해 남는 잡음 수준을 측정함으로써, 사전 지식이나 특징 설계 없이도 생성 과정을 비교할 수 있는 보편적 유사성 지표를 제시한다.
상세 분석
본 논문은 임의의 연속 데이터 스트림을 유한 기호 알파벳으로 양자화하고, 이를 확률적 유한 상태 자동기(PFSA)라는 숨은 생성 모델에 대응시킨다. PFSA 공간은 가환군 구조를 가지며, 각 모델 G에 대해 유일한 역원 G가 존재한다. 역원 모델과 원 모델을 합하면 ‘평탄 백색 잡음(FWN)’을 생성하는 영원 모델 W가 된다. 데이터 스매싱은 실제 관측된 기호열 s에 대해 직접적인 모델 복원 없이, 알고리즘적으로 s의 안티‑스트림 s를 생성하고, 이를 다른 스트림 t와 합성한다. 합성 결과가 FWN에 얼마나 가까운지를 ‘편차 ^ ☐(·)’ 함수로 정량화하며, 이 값이 작을수록 두 스트림이 동일한 생성 과정을 공유한다는 의미이다.
핵심 알고리즘은 네 가지 기본 연산으로 구성된다. ① 독립 스트림 복사(Independent Stream Copy)는 FWN으로부터 무작위 심볼을 읽어 원 스트림과 일치할 때만 출력한다. ② 스트림 역전(Stream Inversion)은 다중 독립 복사본을 이용해 모든 복사본에서 동일한 심볼이 나타날 때만 출력함으로써 통계적 반대를 구현한다. ③ 스트림 합성(Stream Summation)은 두 스트림의 현재 심볼이 일치할 경우에만 출력한다. ④ 편차 계산(Deviation from FWN)은 모든 길이 ℓ≤L 에 대해 관측된 조건부 분포와 균등 분포의 차이를 가중합해 ^ ☐ 값을 산출한다. 여기서 L 은 입력 길이에 대한 로그 스케일 함수이며, 충분한 데이터가 확보되면 ^ ☐ 값은 0에 수렴한다.
이론적으로는 PFSA가 유한 상태, 정상성, 에르고딕성을 만족하면 위 연산이 정확히 정의되고, 두 스트림 사이의 거리 d(G,H)=^ ☐(G+ H) 는 메트릭 성질(비음성, 대칭, 삼각 부등식)을 만족한다. 따라서 관측된 기호열만으로도 숨은 모델 간 거리를 추정할 수 있다.
실험에서는 뇌전증 EEG, 심장 리듬, 천문학적 광도곡선 등 서로 다른 도메인에서 데이터 스매싱을 적용하였다. 특징 설계 없이도 기존 도메인 전문가 기반 알고리즘과 동등하거나 우수한 분류 정확도를 달성했으며, 특히 데이터 양이 충분히 크면 자동으로 최적 알파벳 크기와 양자화 방식을 선택할 수 있다.
제한점으로는 완전히 결정론적인 시스템(예: 주기적 신호)에서는 PFSA 모델이 의미를 갖지 않으며, 스트림 간 독립성이 크게 위배될 경우(공통 외부 요인에 의해 강하게 상관된 경우) 결과가 왜곡될 수 있다. 또한 거리 계산에 필요한 문자열 길이가 길어질수록 계산량이 알파벳 크기의 제곱에 비례해 증가하므로, 실시간 초고속 스트림에는 적절한 알파벳 축소와 샘플링 전략이 필요하다.
요약하면, 데이터 스매싱은 “통계적 반대”라는 새로운 개념을 도입해, 특징 추출이나 지도 학습 없이도 데이터 스트림 간의 근본적인 생성 메커니즘을 비교·클러스터링할 수 있는 보편적 프레임워크를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기