이미지 토픽 자동 발견을 위한 스파스 주성분 분석 기반 TOP‑SPIN
초록
TOP‑SPIN은 Bag‑of‑Words 방식으로 만든 시각 단어 히스토그램 행렬에 스파스 PCA를 적용하고, 각 스파스 주성분과 이미지 히스토그램 간의 내적(Interference)을 이용해 토픽을 자동으로 추출한다. Alternating Maximization(AM) 기반의 효율적인 스파스 PCA 솔버와 결합된 deflation 기법을 통해 다중 토픽을 빠르게 찾으며, 실험에서 이미지 카테고리 예측 및 토픽 발견 성능이 기존 방법보다 우수함을 보인다.
상세 분석
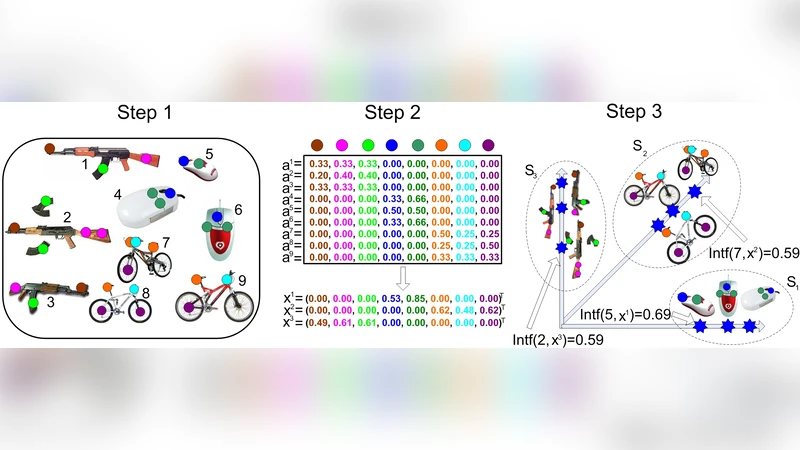
본 논문은 비지도 이미지 데이터베이스에서 의미 있는 토픽(즉, 이미지 집합)을 자동으로 식별하는 새로운 프레임워크 TOP‑SPIN을 제안한다. 핵심 아이디어는 BoW(Bag‑of‑Words) 모델을 이용해 각 이미지를 시각 단어 빈도 히스토그램으로 표현하고, 이 행렬에 스파스 주성분 분석(sparse PCA)을 적용해 시각 단어들의 희소한 공동 발생 패턴을 찾아내는 것이다. 스파스 PC는 제한된 수의 시각 단어만을 비제로로 갖으며, 해당 단어들이 동시에 나타나는 이미지 집합을 의미한다.
스파스 PC를 구하는 최적화 문제는 ‖A x‖₂²를 최대화하면서 ‖x‖₀≤s, ‖x‖₂≤1이라는 제약을 두는 형태이며, 여기서 A=H·Diag(w)이며 w는 TF‑IDF와 같은 가중치 벡터이다. 저자는 이 문제를 Alternating Maximization(AM) 기반의 24AM 알고리즘으로 해결한다. 24AM은 x와 y(=A x/‖A x‖₂)를 번갈아가며 업데이트하고, s개의 가장 큰 절대값 요소만 남기는 hard‑thresholding 연산 Tₛ를 사용한다. 기존의 Augmented Lagrangian Method(ALM)와 비교해, 24AM은 목표 희소도 s를 직접 제어할 수 있어 파라미터 튜닝이 필요 없으며, 실행 시간도 p가 커질수록 3~4자리 빠르게 수렴한다.
스파스 PC를 순차적으로 추출하기 위해 deflation 방식을 적용한다. 첫 번째 PC x₁을 구한 뒤, A₁←A₀−x₁x₁ᵀ 형태로 행렬을 업데이트하고, 동일한 절차를 k번 반복한다. 이렇게 얻은 x₁,…,x_k는 서로 직교하면서도 각기 다른 시각 단어 집합을 강조한다.
토픽 할당 단계에서는 각 이미지 i와 PC xₗ 사이의 Interference를 정의한다. Interference(i, xₗ)=|hᵢ·w·xₗ|=|⟨aᵢ, xₗ⟩|이며, 이는 이미지 히스토그램에 가중치를 곱한 뒤 PC와의 내적 크기를 의미한다. 값이 클수록 이미지가 해당 PC가 나타내는 시각 단어 조합을 많이 포함한다는 뜻이다. 저자는 모든 이미지에 대해 Interference를 계산하고, 2‑클러스터링(고/저)으로 임계값 δₗ을 정해 Interference>δₗ인 이미지들을 토픽 Sₗ에 포함시킨다.
실험에서는 3가지 공개 이미지 데이터셋(예: Caltech‑101, VOC 등)에서 자동 토픽 발견과 카테고리 예측을 수행하였다. 결과는 (1) 스파스 PC가 직관적인 시각 단어 그룹을 형성해 의미 있는 토픽을 드러내고, (2) Interference 기반 할당이 정확한 이미지‑토픽 매핑을 제공함을 보여준다. 또한, 24AM 기반 SPCA가 기존 SDP‑기반 ALM보다 100‑1000배 빠르게 수렴하면서도 동일하거나 더 높은 정확도를 달성한다는 점을 강조한다.
이와 같이 TOP‑SPIN은 (i) 시각 단어 가중치와 스파스 PCA를 결합해 고차원 BoW 행렬에서 핵심 패턴을 효율적으로 추출하고, (ii) 간단한 내적 기반 인터페이스를 통해 토픽을 정의·할당함으로써, 라벨이 없는 대규모 이미지 컬렉션에서도 의미 있는 카테고리 구조를 자동으로 발견할 수 있다. 다만, 시각 단어 사전 크기와 희소도 파라미터 s에 대한 민감도가 존재하며, 복잡한 배경이나 다중 객체가 혼재하는 경우 토픽 경계가 흐려질 수 있다는 제한점도 논의된다.
댓글 및 학술 토론
Loading comments...
의견 남기기