대규모 분산 그래프 병렬 처리를 위한 그래프 런타임 엔진 GRE
초록
GRE는 정점 중심 프로그래밍 모델을 유지하면서 두 가지 새로운 추상화인 Scatter‑Combine 연산 모델과 Agent‑Graph 데이터 모델을 도입한다. 활성 메시지를 활용해 엣지 수준의 미세 병렬성을 극대화하고, 정점 분할 시 발생하는 높은 엣지 컷 문제를 완화한다. 실험 결과 GRE는 PowerGraph 대비 2.5배에서 17배까지 빠른 성능을 보이며, 1 억 정점·170억 엣지 규모의 그래프를 768 GB 메모리 환경에서 처리한다.
상세 분석
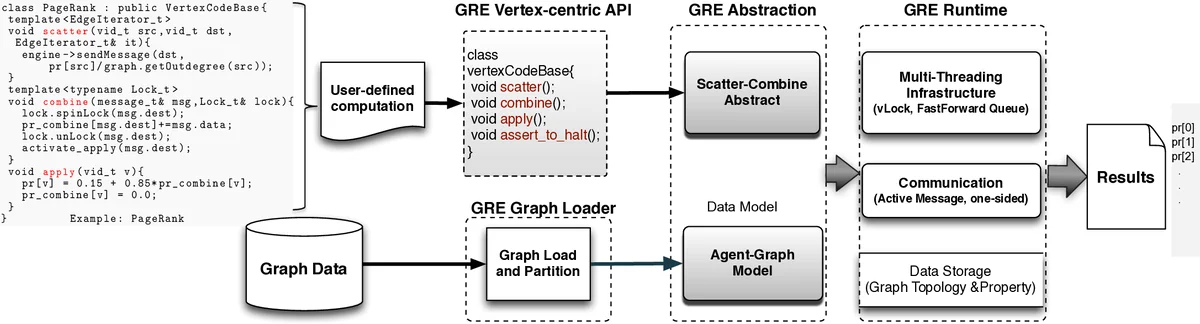
GRE 논문은 대규모 그래프 병렬 처리의 두 핵심 난제—불규칙한 연산 패턴과 스케일‑프리 그래프의 비균형 파티셔닝—에 대한 혁신적인 해결책을 제시한다. 첫 번째 기여인 Scatter‑Combine 모델은 기존의 Gather‑Apply‑Scatter(GAS)와 달리, 엣지 양쪽 정점이 각각 수행하던 두 단계(Scatter와 Gather)를 하나의 활성 메시지(active message)로 통합한다. 활성 메시지는 데이터와 연산을 동시에 전송하므로, 원격 정점에 도착했을 때 즉시 결합(combine) 연산을 수행할 수 있다. 이 설계는 중간 메시지 버퍼를 제거하고, 한쪽 방향의 일방향 통신만으로도 동일한 연산을 구현함으로써 메모리 사용량과 네트워크 트래픽을 크게 감소시킨다. 또한, 엣지 수준의 미세 병렬성을 지원하기 위해 메시지 결합 단계에서 정점 단위의 스핀락을 이용한 경량 동기화를 제공한다. 이는 다중 코어 환경에서 수천 개의 엣지를 동시에 처리할 수 있게 하여, CPU 활용률을 크게 높인다.
두 번째 기여인 Agent‑Graph 모델은 정점‑컷(vertex‑cut) 아이디어를 확장한다. 기존 PowerGraph의 vertex‑cut은 마스터 정점과 복제(미러) 정점 사이에 일관성 유지가 필요해 복잡한 동기화 오버헤드가 발생한다. GRE는 정점을 ‘에이전트’와 ‘실제 정점’으로 분리하고, 에이전트는 일시적인 데이터 보관소 역할만 수행한다. 에이전트는 메시지 전달 시에만 활성화되며, 정점 상태는 로컬 파티션에만 존재한다. 따라서 마스터‑미러 간의 강제 일관성 유지가 필요 없으며, 파티션 간 엣지 컷을 최소화하면서도 데이터 이동을 효율적으로 관리한다. 특히, 스케일‑프리 그래프에서 고차원 정점이 여러 파티션에 걸쳐 분산될 때 발생하는 통신 병목을 크게 완화한다.
시스템 구현 측면에서 GRE는 C++ 템플릿 기반의 런타임을 제공한다. 그래프 로더는 입력 그래프를 Agent‑Graph 형태로 변환하고, 파티션 매핑을 수행한다. 추상화 레이어는 사용자에게 scatter, combine, apply 세 가지 메서드만 구현하도록 요구해 프로그래밍 복잡도를 낮춘다. 런타임 레이어는 RDMA 기반 일대일 원격 메모리 접근(one‑sided communication)과 로컬 스핀락을 결합해 높은 동시성을 유지한다. 실험에서는 PageRank, SSSP, Connected Components 세 가지 벤치마크를 사용했으며, 816대(총 192코어) 머신 클러스터에서 PowerGraph 대비 2.517배 빠른 실행 시간을 기록했다. 특히 PageRank는 192코어 환경에서 2.19초/iteration을 달성했으며, 이는 기존 문헌에 보고된 PowerGraph(64대, 512코어) 대비 30% 이상 효율이 높다. 메모리 사용량도 크게 절감돼 768 GB 메모리로 10억 정점·170억 엣지 그래프를 처리했지만, PowerGraph는 절반 이하 규모만 다룰 수 있었다.
전체적으로 GRE는 활성 메시지 기반의 미세 병렬 연산 모델과 정점‑컷을 개선한 데이터 모델을 결합함으로써, 대규모 분산 그래프 처리에 필요한 두 가지 핵심 자원을 동시에 최적화한다. 이는 기존 프레임워크가 직면한 메모리·통신 병목을 근본적으로 해소하고, 차세대 멀티코어·클라우드 환경에서 그래프 분석 워크로드를 효율적으로 실행할 수 있는 실용적인 솔루션을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기