소셜미디어 텍스트마이닝으로 본 2013년 스톡홀름 폭동
본 연구는 2013년 스톡홀름 폭동을 주제로 트위터와 폴란드인 커뮤니티 포럼(Poloniainfo.se)에서 수집한 텍스트 데이터를 텍스트마이닝·자연어처리 기법으로 분석한다. 해시태그 빈도, 연관 네트워크, 감성 분석을 통해 경찰·정치에 대한 부정적 여론이 주를 이루며, 정체성·고용·주거 문제가 논의의 핵심이라는 점을 확인한다.
저자: Andrzej Jarynowski, Amir Rostami
본 논문은 2013년 5월 스톡홀름에서 발생한 폭동을 사회적 현상으로 바라보고, 소셜미디어가 어떻게 사건을 재현하고 확산시키는지를 텍스트마이닝과 자연어처리(NLP) 기법을 통해 탐색한다. 연구자는 두 가지 온라인 커뮤니케이션 채널을 선택했으며, 하나는 전 세계적으로 사용되는 마이크로블로그인 트위터, 다른 하나는 스웨덴에 거주하는 폴란드인 커뮤니티 포럼인 Poloniainfo.se이다. 두 데이터셋 모두 공개적으로 크롤링이 가능하다는 점에서 ‘빅데이터’ 분석 대상으로 적합하다고 판단했지만, 각각의 사용자 군이 매우 특수하고 편향돼 있다는 점을 서론에서 명시한다.
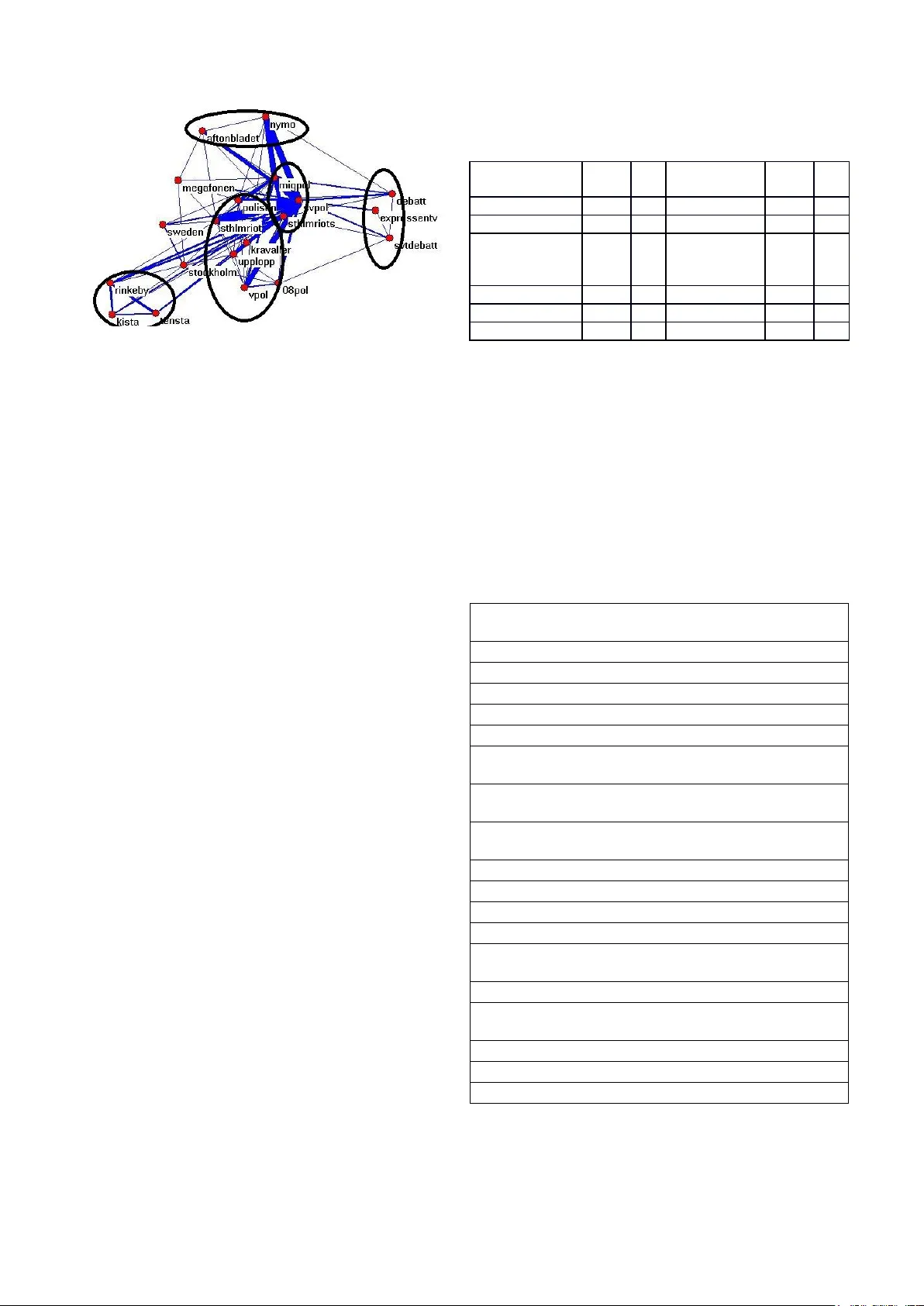
트위터 데이터는 2013년 5월 15일부터 7월 15일까지 약 14 000개의 트윗을 수집했으며, 해시태그가 두 개 이상 포함된 8 000개의 트윗만을 분석에 사용한다. 가장 빈번한 해시태그 20개를 표로 정리하고, ‘Svpol(스웨덴 정치)’이 3 897회로 가장 많이 등장했으며, ‘Sthlmriots’, ‘Migpol(이민 정치)’ 등이 뒤를 이었다. 시간적 누적 그래프를 통해 ‘Svpol’과 ‘Migpol’은 사건 전후로 일정한 발생률을 보이며 선형적인 증가곡선을 그리는 반면, ‘Debatt’, ‘Svtdebatt’ 등은 폭동이 일어나는 기간에만 급증한다는 점을 확인한다. 이는 정치적 논의가 사건과 무관하게 지속되는 현상과, 일반 토론이 사건 중심으로 일시적으로 활성화되는 현상을 동시에 보여준다.
연관 분석에서는 동일 트윗 내에 동시에 등장한 해시태그 쌍을 2‑gram으로 정의하고, 가장 빈번한 조합은 ‘sthlmriots_svpol’(533회)과 ‘svpol_migpol’(353회)임을 보고한다. 이 두 조합을 네트워크 상에서 두꺼운 링크로 표시하고, 나머지 해시태그는 얇은 링크로 시각화한다. 결과적으로 정치 관련 해시태그가 중심축을 이루며, 지리적 구역(예: Rinkeby, Tensta)이나 언론사 해시태그가 주변 클러스터를 형성한다. 저자는 이러한 네트워크 구조가 기존 연구에서 제시된 ‘미디어 단계적 확산’ 패턴과 일치한다고 주장한다.
Poloniainfo.se 포럼 데이터는 525개의 게시글에서 폴란드어 단어만을 추출해 386개의 고유 단어를 선정하고, 이를 10개의 대분류와 14개의 소분류로 코딩한다. 가장 눈에 띄는 특징은 ‘그들(oni)’이라는 3인칭 복수 대명사의 빈도가 높아, 포럼 이용자들이 ‘우리’와 ‘그들’이라는 이분법적 시각으로 사건을 서술한다는 점이다. 카테고리별 빈도 분석 결과, 정체성(스웨덴인 vs. 이주민), 경찰(부정적·중립적), 고용·주거 문제가 주요 논의 주제로 나타난다. 특히 ‘정체성’ 카테고리가 전체 단어 중 가장 많이 언급되었으며, 이는 포럼 이용자들이 자신들을 ‘스웨덴 사회에 동화된 외부인’으로 인식하고 있음을 시사한다.
감성 분석은 ‘police’와 연관된 2‑gram을 대상으로 수행했으며, 감성 점수는 -4(매우 부정)에서 +4(매우 긍정)까지 부여한다. 전체 감성 점수는 -5로, 약간의 부정적 경향을 보인다. 가장 빈번한 2‑gram 중 ‘policja uż ywa(경찰이 사용한다)’는 중립, ‘mordować policja(경찰이 살해한다)’는 강한 부정을 나타낸다.
논문의 결론 부분에서는 두 데이터셋 모두 표본 규모와 편향성, 코딩 주관성 등의 한계를 인정한다. 트위터는 국제적 사용자와 다양한 언어가 혼재해 해시태그 중심의 분석이 내용 깊이를 제한하고, 포럼은 폴란드어 사용자에 국한돼 일반 스웨덴 여론을 대변하기 어렵다. 또한, 네트워크 시각화와 빈도 분석에 머무르고, 통계적 검증이나 예측 모델링이 부재한 점을 지적한다. 향후 연구 방향으로는 LDA 기반 토픽 모델링, 딥러닝 감성 분류, 다중 플랫폼 데이터 통합, 그리고 설문조사와 같은 정성적 방법을 결합해 보다 정교한 가설 검증을 제안한다.
전체적으로 이 연구는 소셜미디어 텍스트 데이터를 활용해 폭동 관련 여론의 구조적 특성을 탐색한 초기 시도이며, 정치·경찰에 대한 부정적 감정, 정체성·고용·주거 문제의 논의가 두드러진다는 점을 확인한다. 다만 방법론적 한계와 표본 편향을 보완해야 보다 일반화 가능한 결론을 도출할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기