문서 모델링을 위한 딥 볼츠만 머신
이 논문은 대규모 비구조화 문서 집합에서 잠재 의미 표현을 학습하기 위해 두 개의 은닉층을 갖는 딥 볼츠만 머신(Over‑Replicated Softmax)을 제안한다. 파라미터 공유와 효율적인 사전학습 기법을 통해 학습 비용을 제한하면서도 기존 Replicated Softmax보다 높은 로그우도와 우수한 분류·검색 성능을 달성한다.
저자: Nitish Srivastava, Ruslan R Salakhutdinov, Geoffrey E. Hinton
본 논문은 대규모 비구조화 문서 집합으로부터 의미 있는 잠재 표현을 학습하기 위한 새로운 딥 볼츠만 머신(Deep Boltzmann Machine, DBM) 모델을 제안한다. 기존의 토픽 모델링 접근법은 크게 두 갈래로 나뉜다. 첫 번째는 LDA, CTM 등과 같은 유향 그래프 모델로, 단어-문서 행렬을 확률적 토픽 분포로 설명한다. 이들 모델은 사전 분포를 명시적으로 정의하지만, 정확한 추론이 어려워 변분 추정, Gibbs 샘플링 등 복잡한 알고리즘을 필요로 한다. 두 번째는 Replicated Softmax(RSM)와 같은 무향 그래프 모델이다. RSM은 각 단어를 softmax 가시 유닛으로 복제하고, 이들을 공유된 가중치 행렬을 통해 이진 은닉 토픽 유닛에 연결한다. 이 구조는 가시층에 대한 조건부 분포가 정확히 계산 가능하고, Contrastive Divergence를 이용한 효율적인 학습이 가능하지만, 은닉층이 단일 RBM에 머물러 사전(prior) 표현이 고정적이다.
이러한 배경에서 저자들은 “Over‑Replicated Softmax”라는 두 은닉층을 갖는 DBM을 설계한다. 첫 번째 은닉층 h^(1)은 RSM과 동일하게 이진 토픽 유닛이며, 두 번째 은닉층 H^(2)는 softmax 형태의 복제 유닛 M개로 구성된다. 핵심 설계는 가시층 V와 두 번째 은닉층 H^(2) 사이의 가중치와 바이어스를 완전히 공유한다는 점이다. 즉, W^(1)_{ijk}=W^(2)_{ijk}=W_{jk}, b^(1)_{ik}=b^(2)_{ik}=b_k 로 설정한다. 이로써 모델 전체 파라미터 수는 기존 RSM과 동일하게 유지되면서도, H^(2)가 제공하는 추가적인 사전이 h^(1)의 분포를 보다 유연하게 만든다.
수식적으로는 문서 길이 N과 두 번째 은닉층 크기 M을 이용해 에너지 함수를 단순화한다. ˆv_k는 문서 내 단어 k의 등장 횟수, ˆh^(2)_k는 H^(2)에서 k번째 단어가 차지하는 총 카운트이다. 에너지식은 −∑_{j,k}W_{jk} h^(1)_j (ˆv_k+ˆh^(2)_k) −∑_k (ˆv_k+ˆh^(2)_k) b_k −(M+N)∑_j h^(1)_j a_j 로 표현된다. 이때 M/N 비율에 따라 사전의 강도가 조절된다; M≈N이면 두 은닉층이 동일한 역할을 수행해 사전이 두 배가 되고, N≫M이면 첫 번째 은닉층이 주도한다.
학습은 두 단계로 진행된다. (1) 효율적인 사전학습(Pretraining) 단계에서는 파라미터 공유 덕분에 DBM을 단일 RBM처럼 학습한다. N과 M이 동일하면 bottom‑up 가중치를 2배 스케일링한 형태로 CD‑1을 적용하면 된다. N과 M이 다를 경우에는 (1+M/N) 배로 스케일링한다. 이 과정은 초기 파라미터를 좋은 영역으로 이동시켜 이후 복잡한 DBM 학습의 수렴을 돕는다. (2) 정식 학습 단계에서는 변분(mean‑field) 추정과 MCMC 기반 스토캐스틱 근사를 결합한다. 완전 팩터화된 변분 분포 Q(h|V;µ)=∏_j q(h^(1)_j|V)∏_i q(h^(2)_i|V) 를 사용해 데이터 의존 기대값을 근사하고, Gibbs 샘플링을 통해 모델 기대값을 추정한다. 변분 파라미터 µ는 고정점 방정식 µ^(1)_j←σ(∑_k W_{jk}(ˆv_k+M µ^(2)_k)), µ^(2)_k←softmax(∑_j W_{jk} µ^(1)_j) 로 업데이트한다. 학습 중 각 문서마다 짧은 Gibbs 체인을 실행하고, 초기 상태를 µ^(1)에서 샘플링한 값으로 설정해 샘플링 효율을 높인다.
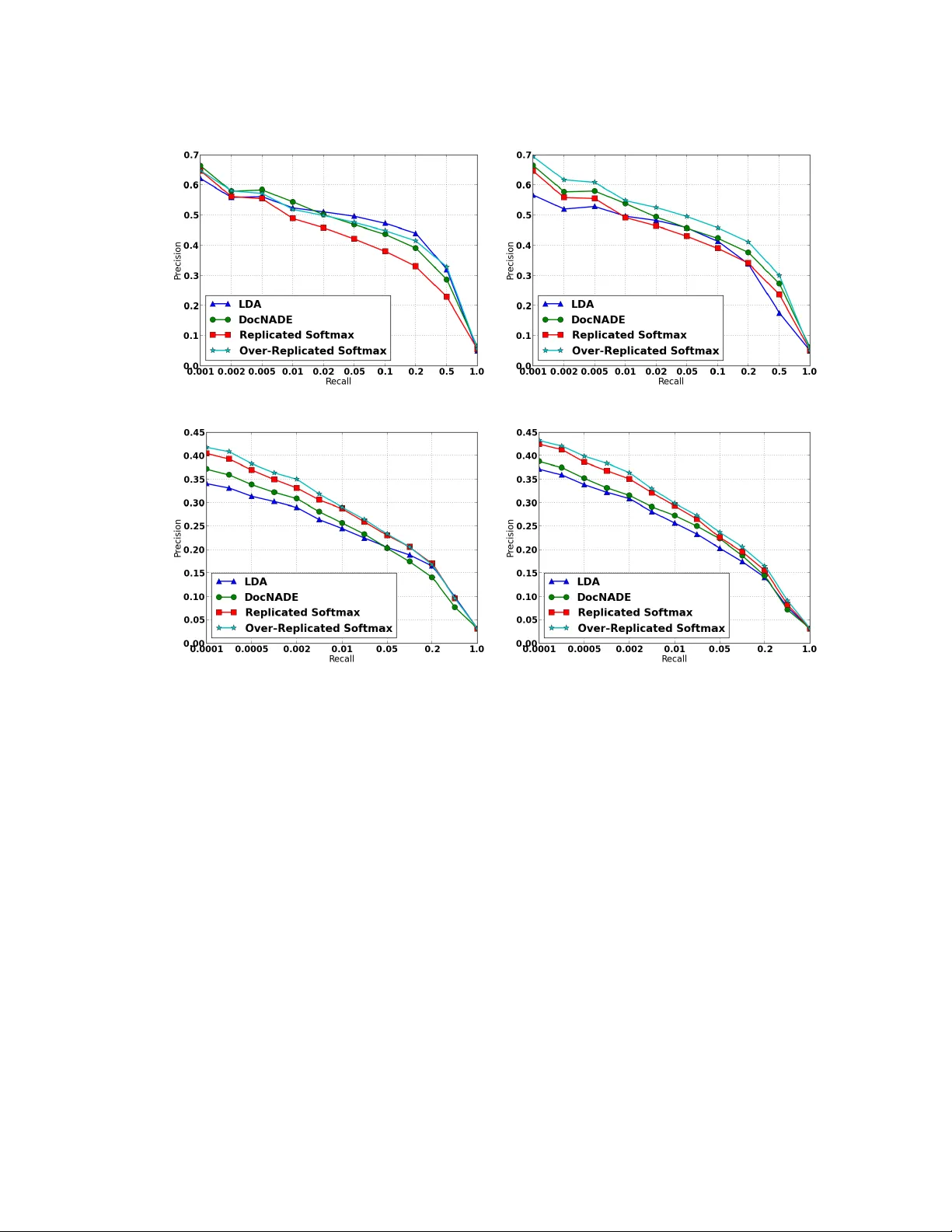
실험은 20 Newsgroups와 Reuters-21578 데이터셋을 사용했다. 로그우도 측면에서 Over‑Replicated Softmax는 RSM보다 현저히 높은 값을 기록했으며, 이는 두 번째 은닉층이 제공하는 유연한 사전이 데이터 적합도를 크게 향상시켰음을 의미한다. 문서 검색(task: nearest‑neighbor based on latent vectors)과 문서 분류(task: SVM on latent features)에서도 LDA, DocNADE, RSM에 비해 일관된 성능 우위를 보였다. 특히 짧은 문서(N≪M)에서는 두 번째 은닉층이 사전 역할을 크게 담당해 성능 차이가 두드러졌다. 파라미터 수가 동일함에도 불구하고, 모델 구조만으로 일반화 능력이 크게 개선된 점이 주요 기여이다.
결론적으로, 본 연구는 파라미터 공유와 효율적인 사전학습을 통해 DBM 기반 토픽 모델을 실용적인 수준으로 끌어올렸다. 복잡한 비지도 학습 모델이 대규모 텍스트 코퍼스에 적용 가능함을 실증했으며, 향후 더 깊은 계층, 멀티모달 확장, 최신 변분 추정 기법 도입 등을 통해 학습 효율성과 표현력을 더욱 강화할 여지를 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기