불확실성을 활용한 확률적 순위 통합
본 논문은 부분 순위 입력에서 발생하는 불확실한 순위 정보를 확률적 모델로 표현하고, 기존 명시적(rank‑explicit) 방법을 기대값 형태로 변형한 새로운 프레임워크 St.Agg를 제안한다. 이를 통해 비지도와 지도 학습 두 시나리오 모두에서 기존 명시·암시 방법들을 능가하는 성능을 입증한다.
저자: Shuzi Niu, Yanyan Lan, Jiafeng Guo
1. 서론
순위 집계는 메타검색, 협업 필터링, 크라우드소싱 등 다양한 응용 분야에서 다수의 순위 입력을 하나의 합의 순위로 통합하는 핵심 문제이다. 기존 연구는 순위 정보를 직접 활용하는 명시적 방법과, 순위로부터 파생된 쌍대 선호나 리스트‑와이즈 정보를 이용하는 암시적 방법으로 크게 두 갈래로 나뉜다. 직관적으로 순위 정보가 핵심임에도 불구하고, 실제 데이터셋에서는 명시적 방법이 암시적 방법보다 성능이 뒤처지는 현상이 관찰된다. 저자들은 이를 부분 순위 입력이 불완전하고, 누락된 아이템으로 인해 순위값이 신뢰성을 잃기 때문이라고 분석한다.
2. 배경 및 기존 방법
비지도 상황에서는 Borda Count, Reciprocal Rank Fusion(RRF) 등 명시적 방법이 각 아이템의 순위값을 평균하거나 역순위 가중치를 부여해 점수를 산출한다. 암시적 방법은 Kendall’s tau 최소화, 행렬 분해, Plackett‑Luce 모델 등 쌍대 선호를 기반으로 최적화를 진행한다. 지도 상황에서는 RankAgg와 같은 프레임워크가 NDCG, ERR, RBP와 같은 평가 지표를 손실 함수로 직접 사용한다. 그러나 이러한 방법들은 모두 입력 순위가 완전하거나 정확하다는 전제 하에 설계되었다.
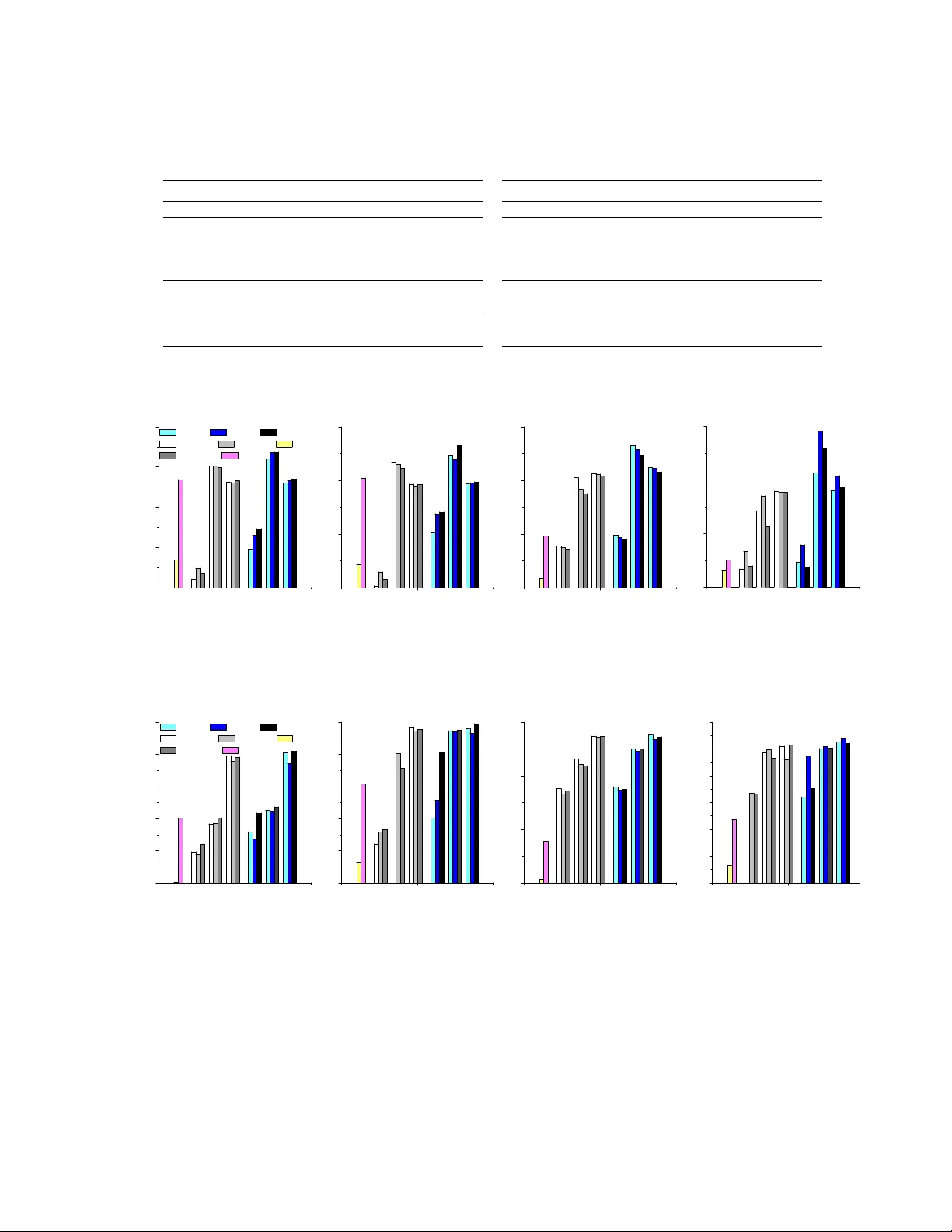
3. 실험적 관찰 및 문제점
LETOR4.0의 MQ2007‑agg와 MQ2008‑agg 데이터셋을 대상으로 실험한 결과, 비지도에서는 SVP, MPM, Plackett‑Luce가 Borda Count, RRF보다 우수했으며, 지도에서는 CPS, θ‑MPM이 RankAgg 계열보다 높은 점수를 기록했다. 특히 부분 순위가 많이 포함된 MQ2007‑agg에서 차이가 두드러졌다. 저자들은 Borda Count 예시를 들어, 누락된 아이템이 있을 경우 남은 아이템의 절대 순위가 왜곡되어 평균 순위가 실제와 크게 달라지는 현상을 시각화한다.
4. 확률적 순위 집계 프레임워크(St.Agg) 설계
4.1 순위 불확실성 모델링
각 아이템 xⱼ에 대해 순위 R(xⱼ, τ)를 “τ 내에서 xⱼ보다 앞서는 아이템 수”로 정의하고, 이를 베르누이 시행의 성공 횟수로 모델링한다. 성공 확률 p(xᵢ ≻ xⱼ)는 쌍대 비교 결과나 기존 암시적 방법에서 추정한다. 초기에는 단일 아이템만 존재하므로 R=0이며, 새로운 아이템이 추가될 때마다 식(10)의 재귀 관계에 따라 분포가 업데이트된다. 최종적으로 P(R = r) 를 얻어 순위의 확률 분포를 구한다.
4.2 비지도 St.Agg
명시적 목표 함수 f(xⱼ)=∑ᵢ u(xⱼ,τᵢ) 를 확률 분포에 대한 기대값 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기