학습 안정적인 다단계 사전학습을 통한 희소 표현
초록
**
본 논문은 대규모 데이터에 적용 가능한 다단계 사전(딕셔너리) 학습 알고리즘을 제안한다. 1‑차원 서브스페이스 군집인 K‑하이퍼라인 클러스터링을 이용해 계층적 사전을 구성하고, 최소 설명 길이(MDL) 원칙으로 각 레벨의 원자 수를 자동 선택한다. 또한, 알고리즘의 안정성·일반화 특성을 이론적으로 증명하고, 랜덤 앙상블 기법으로 제한된 학습 데이터에서도 강인한 사전을 얻는다. 학습된 사전은 저복잡도 다단계 추적(MulP)으로 테스트 데이터의 희소 코드를 빠르게 구할 수 있으며, 압축 복원 및 서브스페이스 학습 등 실험에서 기존 방법을 능가한다.
**
상세 분석
**
본 연구는 희소 코딩 분야에서 ‘전역 사전’의 두 핵심 요구사항인 알고리즘 안정성(stability)과 일반화(generalization)를 동시에 만족시키는 새로운 학습 프레임워크를 제시한다. 핵심 아이디어는 K‑하이퍼라인 클러스터링(K‑hyperline clustering)을 기본 서브스페이스 군집기로 활용해, 각 레벨마다 1‑차원 서브스페이스(즉, 원자)를 추출하고, 그 잔차(residual)를 다음 레벨의 입력으로 사용하는 다단계 구조를 만든다. 이렇게 하면 각 레벨이 서로 독립적인 최소화 문제를 풀게 되므로, 기존 딕셔너리 학습에서 흔히 발생하는 비선형 최적화의 복잡성을 크게 완화한다.
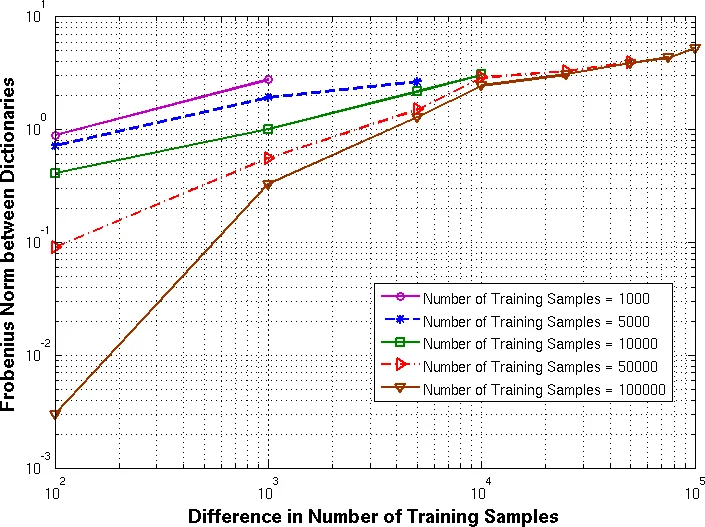
이론적 기여는 크게 네 부분으로 나뉜다. 첫째, K‑하이퍼라인 클러스터링이 ‘uniform Donsker class’에 속함을 보이고, 이를 기반으로 클러스터링 단계의 수렴과 안정성을 증명한다. 논문은 두 개의 i.i.d. 훈련 집합이 동일한 확률분포에서 추출될 때, 훈련 샘플 수 T→∞이면 두 사전이 L₁(P) 거리에서 확률적으로 0에 수렴함을 보인다. 특히, 목표 함수의 최소점이 유일한 경우에는 훈련 집합이 완전히 겹치지 않아도 동일한 수렴을 보장한다. 최소점이 다중인 경우에는 샘플 차이가 o(√T) 이하일 때만 안정성이 유지되고, Ω(√T) 이상의 차이가 있으면 불안정성이 발생함을 명시적으로 제시한다.
둘째, 일반화 분석에서는 경험적 위험(empirical risk)과 기대 위험(expected risk) 사이의 차이가 샘플 수에 대해 O(1/√T)로 수렴함을 보여준다. 이는 기존의 희소 코딩 일반화 경계(예:
댓글 및 학술 토론
Loading comments...
의견 남기기