랜덤 저랭크 행렬 분해의 한계와 최적성: 정확한 성능 경계
본 논문은 널리 사용되는 랜덤 행렬 범위 탐색 알고리즘(Algorithm 1)을 새로운 직관적 분석법으로 재검토한다. 기대 오차를 정확히 결정하는 확률 변수 W를 도입하고, 이를 통해 기존 상한(1.2)의 정확성을 입증함과 동시에 하한을 제시해 상한이 실제로 조밀하게 맞물림을 보인다. 비대칭적인 스펙트럼, 오버샘플링 파라미터 p, 그리고 파워 반복 기법까지 포괄적으로 다루어 실험적으로도 이론적 예측이 매우 타이트함을 확인한다.
저자: Rafi Witten, Emmanuel C, es
1. 서론에서는 대규모 데이터 환경에서 저랭크 근사가 필수적임을 강조하고, 기존 랜덤 알고리즘이 계산 복잡도와 정확도 사이의 균형을 제공한다는 점을 소개한다. 특히 Martinsson 등(2008)의 알고리즘을 중심으로, 그 성능을 보다 정밀히 분석할 필요성을 제기한다.
2. 문제 정의에서는 임의의 m × n 행렬 A를 목표 랭크 ℓ(=k) 로 근사하는 일반적인 형태 A ≈ BC를 제시하고, 성능 평가는 스펙트럼 노름 ‖A‑BC‖₂ 또는 Frobenius 노름 ‖·‖_F 로 측정한다. 최적의 ℓ‑랭크 근사는 SVD 절단에 의해 σ_{ℓ+1}가 오차가 되지만, 이는 O(mnℓ) 비용이 든다.
3. 알고리즘 1은 Gaussian 테스트 행렬 G∈ℝ^{n×ℓ}를 샘플링하고 H=AG를 만든 뒤, H의 열공간을 정규 직교화해 Q∈ℝ^{m×ℓ}를 얻는다. 최종 근사는 QQᵀA이며, 핵심 질문은 ‖(I‑QQᵀ)A‖₂가 σ_{ℓ+1}에 비해 얼마나 큰가이다. 기존 결과(Theorem 1.1)는 기대값 상한 (1.2)를 제공한다.
4. 주요 기여는 Theorem 1.2와 Corollary 1.3이다. 저자들은 ‖(I‑QQᵀ)A‖₂를 σ_{k+1}·W 형태로 정확히 표현한다. 여기서 W는 X₁, X₂, Σ 로 구성된 복합 확률 변수이며, 모든 A에 대해 동일한 분포를 가진다. 또한, 임의의 ε>0에 대해 ‖(I‑QQᵀ)A‖₂ ≥ (1‑ε)σ_{k+1}·W가 되는 최악의 A가 존재함을 보인다. 이는 상한이 실제 최악 오차와 일치함을 의미한다.
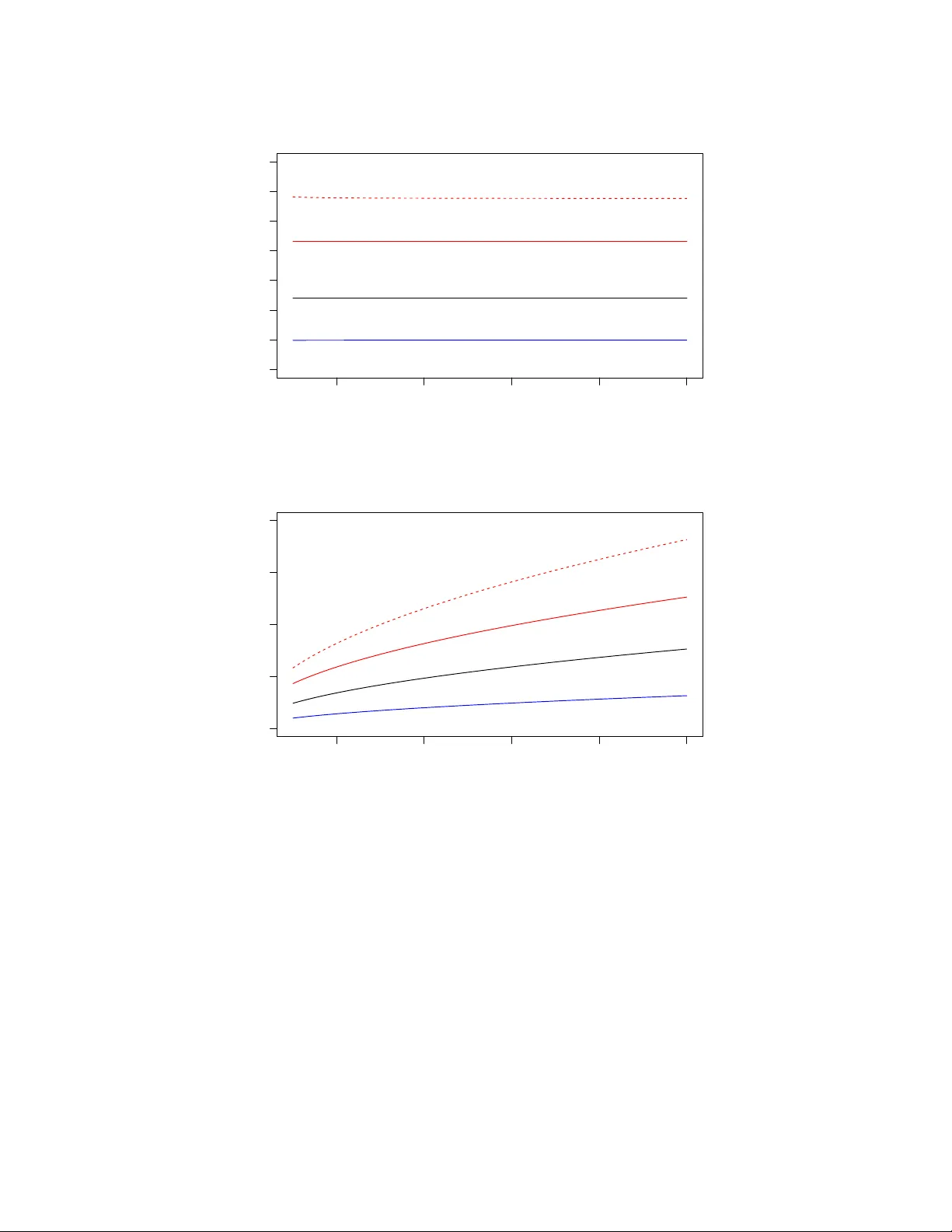
5. W의 기대값을 분석해 비대칭적인 상·하한을 도출한다. 하한은 p·n/(k)·(1/√(p+1)) 형태이며, 상한은 e·√(k+p)/p·(1+√(n‑k)+√k) 등으로, 특히 p를 충분히 크게 잡으면 두 경계가 거의 겹친다. 이는 오버샘플링 파라미터 p가 성능에 결정적 영향을 미친다는 직관을 수학적으로 뒷받침한다.
6. 대규모 한계에서는 n→∞, k,p→∞, p/k→ρ>0 조건 하에 W가 거의 확정값 √(n‑k)+√k·√(k+p)‑√k 로 수렴한다. 이는 식 (1.6)·(1.7)·(1.8)에서 명시되며, 실제 실험에서도 오차가 거의 변동 없이 한 값에 집중함을 확인한다.
7. 기존 분석과의 차별점은 ‘모노톤성’ 레마(2.1)를 이용해 스펙트럼이 큰 행렬이 작은 행렬보다 큰 오차를 만든다는 단순한 순서 관계를 도입한 것이다. 이를 통해 최악의 입력을 명시적으로 구성하고, 그 경우의 오차가 바로 W임을 증명한다.
8. 실험 섹션에서는 최악의 입력 행렬을 직접 생성해 n=10⁴‒10⁵, k와 p를 다양한 비율로 설정한 뒤 1000번 이상 시뮬레이션을 수행했다. 결과는 이론적 상·하한 사이에 거의 모든 샘플이 위치하고, 특히 n이 커질수록 분포가 집중(concentration)되는 현상을 보여준다. 또한 파워 반복(Algorithm 3)을 적용하면 오차가 W^{1/(2q+1)} 로 감소함을 확인했으며, q=3일 때도 실용적인 수준의 정확도를 얻는다.
9. 마지막으로, 알고리즘 2를 통해 근사 SVD를 얻는 전체 파이프라인을 제시하고, 파워 트릭을 포함한 확장 가능성을 논의한다. 또한 Gaussian 테스트 행렬이 최적임을 언급하며, 향후 비-Gaussian 테스트 행렬이나 구조적 행렬에 대한 연구 방향을 제시한다.
전체적으로, 본 논문은 랜덤 저랭크 행렬 분해 알고리즘의 성능을 정확히 규정하는 새로운 확률적 프레임워크를 제공하고, 오버샘플링 파라미터와 파워 반복이 어떻게 오차를 제어하는지를 정량적으로 설명한다. 이론적 결과와 실험적 검증이 일치함을 보여줌으로써, 해당 알고리즘이 대규모 데이터 분석에서 신뢰할 수 있는 도구임을 확고히 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기