자동 무작위 테스트의 법칙 탐구
초록
자동 무작위 테스트를 이용해 소프트웨어 결함 수를 추정하려는 시도를 다룬 논문이다. 대규모 테스트 데이터를 기반으로 다양한 수학적 모델을 피팅한 결과, 다항 로그 형태가 가장 적합함을 제시한다.
상세 분석
본 연구는 자동 무작위 테스트(Automated Random Testing, ART)가 결함 탐지 효율성을 높이는 동시에, 남아있는 결함 수를 정량적으로 예측할 수 있는 법칙을 제공할 가능성을 탐색한다. 저자들은 먼저 계약 기반 오라클(Design by Contract)를 활용해 Eiffel 및 Java 라이브러리의 30여 개 모듈을 대상으로 수백만 회의 무작위 호출을 수행하였다. 테스트 대상은 표준 컬렉션, 입출력, 문자열 처리 등 다양한 기능을 포함하고 있어, 결과의 일반화 가능성을 확보하려는 의도가 엿보인다.
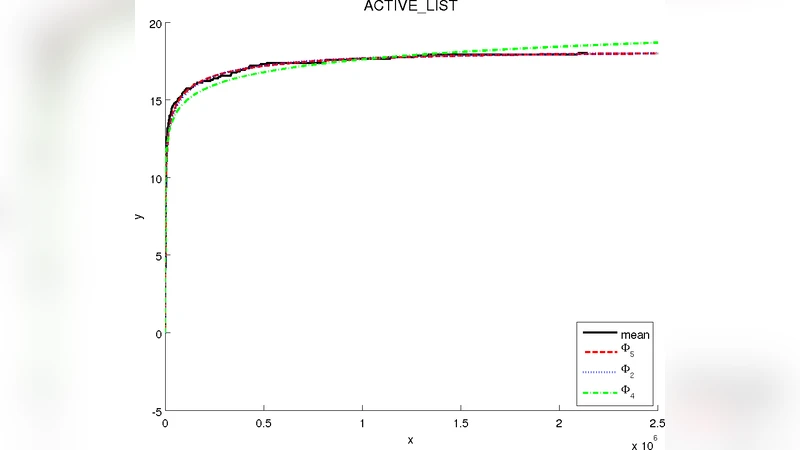
데이터 수집 단계에서 각 테스트 케이스가 발견한 고유 결함 수를 시간(또는 테스트 케이스 수) 함수로 기록하였다. 이후 저자들은 20여 개의 후보 함수(지수, 로그, 다항, 다항 로그, 하이퍼볼릭 등)를 비선형 최소제곱법으로 피팅하고, AIC·BIC·R² 등 통계적 지표를 통해 모델 적합도를 비교하였다. 특히, f(t)=a·logⁿ(t)+b 형태의 다항 로그 함수가 다른 모델에 비해 잔차가 가장 작고, 장기 추세를 안정적으로 설명한다는 점이 강조된다.
다항 로그 모델이 의미하는 바는 테스트가 진행될수록 결함 발견률이 급격히 감소하지만, 완전히 0에 수렴하지는 않으며, 로그 스케일에서 점진적인 감소를 보인다는 것이다. 이는 “테스트가 오래될수록 남은 결함이 점점 더 찾기 어려워진다”는 직관과 일치한다. 또한, 모델 파라미터 a와 n은 테스트 대상의 복잡도와 초기 결함 밀도에 따라 변동하며, 이를 통해 프로젝트 간 비교가 가능하다는 잠재적 활용 가치를 제시한다.
한계점으로는 현재 실험이 계약 기반 오라클이 가능한 제한된 언어와 라이브러리 코드에 국한되었으며, 실제 산업 현장의 대규모 애플리케이션이나 GUI 기반 시스템에는 적용되지 않았다는 점을 들었다. 또한, 무작위 테스트 자체가 특정 유형의 결함(예: 경계 조건, 비정형 입력) 탐지에 편향될 수 있기에, 모델이 모든 결함을 포괄한다고 보기엔 무리가 있다.
결론적으로, 저자들은 다항 로그 법칙이 자동 무작위 테스트에서 남은 결함 수를 추정하는 실용적인 근사식이 될 수 있음을 실증적으로 뒷받침했으며, 향후 다양한 도메인과 테스트 기법을 포함한 확장 연구가 필요함을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기