패킹된 텍스트에서 k 불일치 근사 문자열 매칭
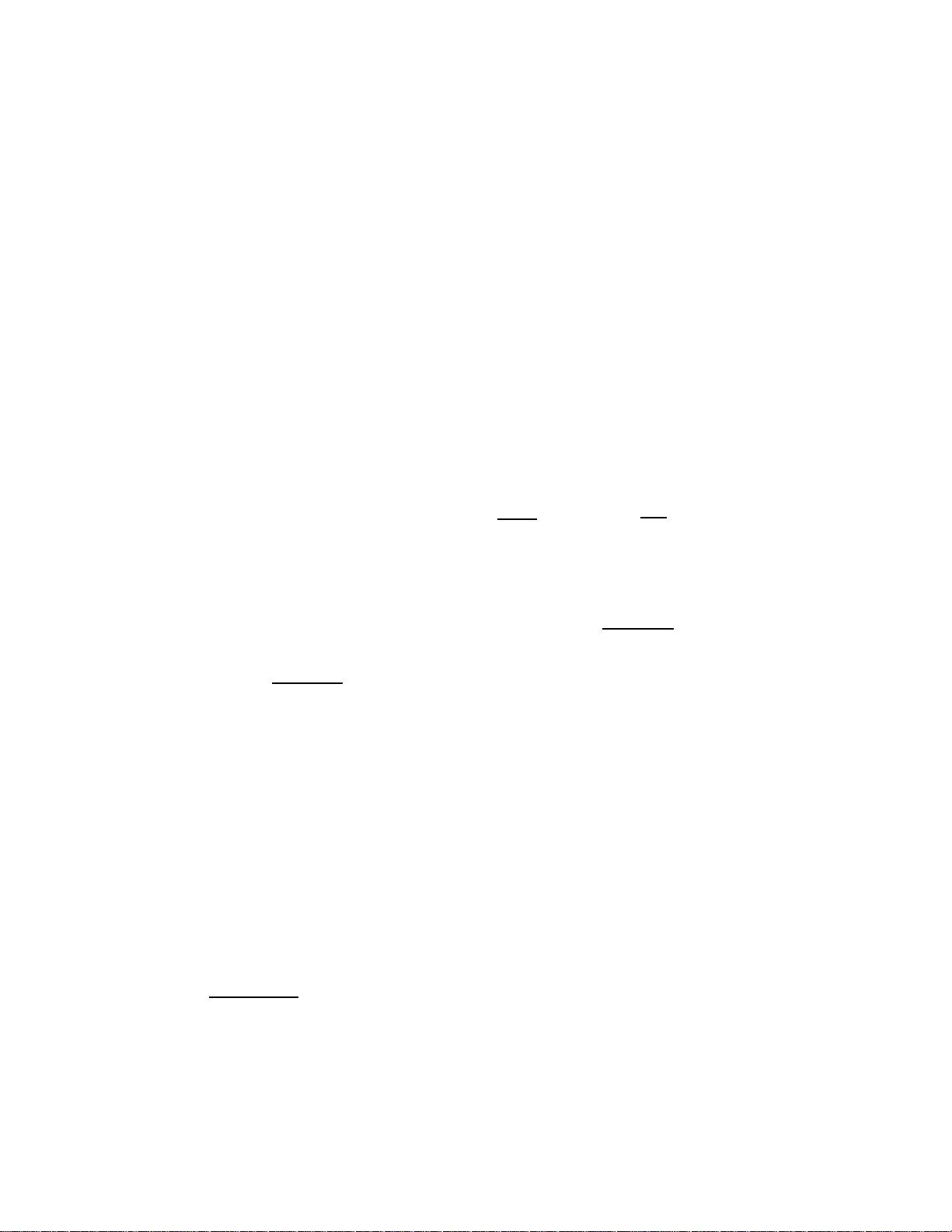
초록
문자열 P와 T가 주어질 때, T의 모든 길이 m 부분문자열 중 Hamming 거리 ≤k 인 위치를 찾는 k‑불일치 매칭 문제를, 문자들을 패킹하여 한 번에 여러 개를 읽을 수 있는 RAM 모델에서 해결한다. 기존 최선 알고리즘보다 워드 길이 w가 로그보다 크게 성장할 경우 더 빠른 시간 복잡도를 제공한다.
상세 분석
이 논문은 문자열 매칭 문제 중에서도 특히 Hamming 거리 기반의 k‑불일치(approximate) 매칭을 다룬다. 전통적인 워드‑RAM 모델에서는 텍스트 T를 한 번에 한 문자씩만 읽을 수 있기 때문에, 최선의 알려진 시간 복잡도는 O(n√{k log k}) 혹은 O(n + n√{k/w} log k) 수준이다. 그러나 실제 메모리에서는 한 워드에 ⌊w / log σ⌋ 개의 문자(σ는 알파벳 크기)를 비트 레벨로 압축(pack)하여 저장할 수 있다. 이때 각 문자당 ⌈log σ⌉ 비트를 사용하므로, 워드 하나에 다수의 문자 정보를 동시에 접근할 수 있다. 기존 연구에서는 이러한 패킹을 활용한 k‑불일치 알고리즘이 O((n log σ / log n)·⌈m log(k+log n / log σ) / w⌉ + n^ε) 시간 복잡도를 보였지만, 이는 m이 워드 길이에 비해 작을 때만 효율적이었다.
본 논문은 두 가지 새로운 알고리즘을 제시한다. 첫 번째는 AC⁰ 모델에서 동작하며, m = O(w / log σ)인 경우에 n / ⌊w/(m log σ)⌋ 배 만큼의 병렬성을 확보한다. 구체적으로 시간 복잡도는
O( n / ⌊w/(m log σ)⌋ · (1 + log min(k,σ)·log m / log σ) )
이다. 여기서 min(k,σ) 항은 문자 알파벳 크기와 허용 불일치 수 중 작은 값을 선택함으로써, 알파벳이 작을 경우 불필요한 로그 연산을 줄인다. 두 번째 알고리즘은 워드‑RAM 모델에 맞춰 설계되었으며, 구현이 더 간단하면서도
O( n / ⌊w/(m log σ)⌋ · log min(m, log w / log σ) )
의 시간 복잡도를 달성한다. 두 알고리즘 모두 텍스트를 패킹된 형태로 제공받는다는 전제 하에, 워드 단위 연산(비트 마스크, 시프트, 병렬 비교 등)을 활용해 여러 위치를 동시에 검사한다.
핵심 기술은 “패킹된 블록 대비 슬라이딩 윈도우”와 “비트‑패턴 매칭”이다. 텍스트 T를 ⌊w/(m log σ)⌋ 개의 블록으로 나누고, 각 블록을 한 번에 로드한다. 이후 패턴 P를 동일한 비트 포맷으로 변환한 뒤, XOR 연산을 통해 문자별 불일치를 비트 마스크로 얻는다. popcount(·) 연산을 이용해 각 블록 내 불일치 개수를 빠르게 합산하고, k 이하인 경우 매칭 위치를 보고한다. 이 과정에서 워드 내부의 병렬성을 최대한 활용하기 위해, 불일치 마스크를 여러 단계에 걸쳐 축소(reduction)하는 트리 구조를 사용한다. 또한, AC⁰ 모델에서는 논리 게이트 수준에서 XOR·AND·OR만을 사용해 동일한 연산을 구현함으로써, 상수 시간 내에 대규모 병렬 처리를 보장한다.
알고리즘의 복잡도 분석에서는 두 가지 주요 파라미터가 등장한다. 첫째는 워드당 처리 가능한 문자 수 ⌊w / log σ⌋ 로, 이는 하드웨어 워드 길이와 알파벳 크기에 직접 비례한다. 둘째는 패턴 길이 m 으로, m이 워드 길이에 비해 작을수록 블록당 처리 효율이 높아진다. 논문은 w = Ω(log^{1+ε} n) (ε>0)인 경우, 기존 최선 알고리즘보다 확연히 작은 상수 계수를 갖는 시간 복잡도를 달성함을 증명한다. 특히, σ가 작아 log σ가 작을 때는 log min(k,σ) 항이 거의 사라져 거의 선형에 가까운 성능을 기대할 수 있다.
마지막으로, 제시된 기술을 확장하여 “k‑오류 편집 거리 매칭”, “와일드카드 포함 매칭”, “다중 패턴 매칭” 등 다양한 근사 문자열 매칭 문제에도 적용 가능함을 보인다. 이러한 확장은 모두 동일한 비트‑패킹·병렬 비교 프레임워크를 기반으로 하며, 각 문제에 맞는 마스크 설계와 popcount 연산 변형만으로 구현할 수 있다. 전체적으로 이 논문은 텍스트를 패킹된 형태로 저장하고, 워드‑레벨 병렬 연산을 활용함으로써 k‑불일치 매칭의 이론적 한계를 크게 확장한 중요한 기여를 한다.