정규화된 PCA로 배우는 고효율 팩터 모델 추정법
초록
본 논문은 기존 PCA 기반 팩터 분석이 샘플 수가 변수 차원보다 적을 때 발생하는 편향을 완화하기 위해, 공분산 행렬의 트레이스에 패널티를 부여하는 정규화 PCA(UTM)와 비균일 잔차분산을 다루는 확장형 STM을 제안한다. 제안 알고리즘은 SDP 형태의 최적화 문제를 근사적으로 풀어 기존 PCA와 동일한 계산 복잡도를 유지하면서도 더 정확한 팩터 로딩과 잔차분산을 추정한다. 이론적 분석과 합성·실제 주가 데이터 실험을 통해 기존 URM 대비 샘플 효율성과 추정 정확도가 크게 향상됨을 입증한다.
상세 분석
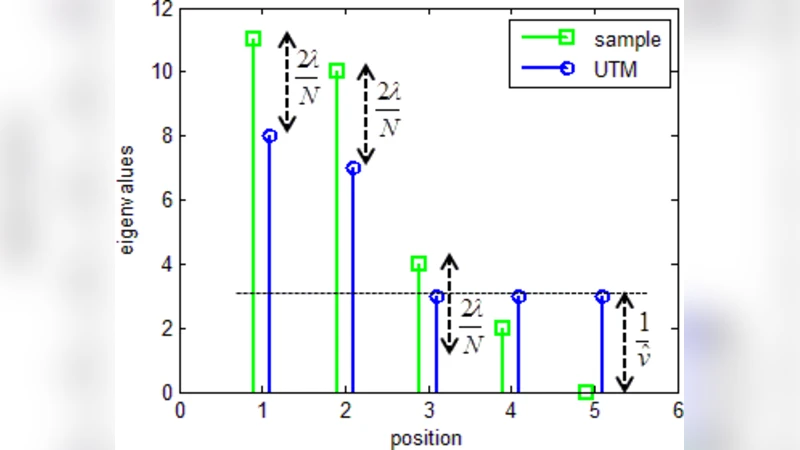
이 논문은 선형 팩터 모델 Σ* = F* + R* 를 추정하는 문제를 “out‑of‑sample likelihood”를 최대화하는 관점에서 재정의한다. 기존 방법인 URM(Uniform‑Residual‑Rank‑Constrained Maximum‑Likelihood)은 샘플 공분산 Σ_SAM의 상위 K개의 고유값을 그대로 사용하고 나머지는 평균으로 대체하는데, 이는 샘플 고유값이 실제 고유값보다 과대평가되는 편향을 내포한다. 저자들은 이를 보정하기 위해 Σ = F + σ²I 형태에서 트레이스(= ∑ eig(F))에 λ·tr(F) 패널티를 추가한 정규화 문제(UTM)를 제시한다. 핵심 아이디어는 Σ⁻¹ = v I − G 로 변환해 G ∈ S⁺_M 로 제한하고, 로그우도는 Σ⁻¹에 대해 볼록함수임을 이용해 convex SDP 형태로 만든 뒤, 고유벡터는 Σ_SAM과 동일하게 유지하면서 고유값을 h_m = max{s_m − 2λ/N, v̂⁻¹} 로 조정한다. 이 과정은 단순히 샘플 고유값을 일정량(2λ/N) 감소시키는 것이며, 이 감소량은 λ를 교차검증으로 선택한다. 결과적으로 큰 고유값은 그대로 유지되면서 과대평가가 교정되고, 작은 고유값은 잔차분산에 흡수돼 전체 트레이스가 보존된다.
이론적으로는 랜덤 행렬 이론을 활용해 고유값의 기대값과 편차를 분석하고, 트레이스 패널티가 샘플 고유값의 “shrinkage” 효과를 제공함을 증명한다. 또한, 비균일 잔차분산을 허용하는 STM은 R을 대각 행렬로 두고, 동일한 트레이스 패널티를 적용한 뒤, 잔차분산을 별도로 추정하는 2‑step 절차를 제안한다.
계산 복잡도 측면에서 SDP를 직접 풀면 O(M³) 이상의 시간이 소요되지만, 제안된 알고리즘은 고유분해 한 번(또는 상위 K개만) 수행하고 O(M) 연산으로 고유값을 조정하므로, 기존 PCA와 동일한 수준의 실행 시간을 보인다. 실험에서는 M = 1000 차원에서 ADMM 기반 SDP는 수시간이 걸리는 반면, 제안 알고리즘은 수초 내에 수렴한다.
실증 결과는 합성 데이터에서 UTM이 URM 대비 2/3 수준의 샘플만으로 동일한 추정 정확도를 달성함을 보여준다. 실제 주가 데이터(다양한 종목의 일일 수익률)에서도 STM이 기존 팩터 분석(예: 정규화된 PCA, EM‑기반 팩터 모델)보다 KL divergence와 예측 로그우도에서 유의미하게 우수함을 확인한다. 또한, 기존 연구(Chandrasekaran et al., 2012)와 비교해 트레이스 패널티가 비대칭(비대칭적) 편향을 감소시키고, 비균일 잔차분산 상황에서도 더 적은 편향을 보임을 강조한다.
요약하면, 이 논문은 (1) 트레이스 패널티를 통한 “soft” 차원 축소, (2) PCA 기반 효율적인 구현, (3) 비균일 잔차분산 확장, (4) 이론적 편향 보정 증명, (5) 실험을 통한 실용성 입증이라는 다섯 축을 통해 기존 팩터 분석의 한계를 크게 완화한다.
댓글 및 학술 토론
Loading comments...
의견 남기기