관측 오류가 있는 상호작용 에이전트 네트워크의 지식 획득
초록
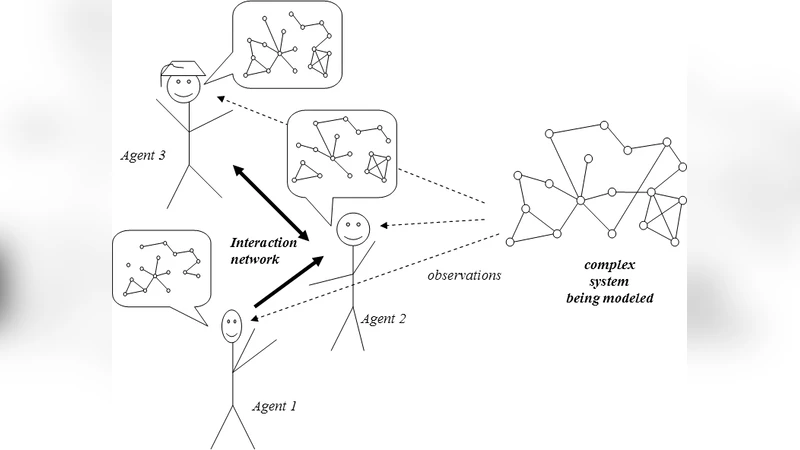
본 연구는 관측 오류가 존재하는 환경에서 다수의 에이전트가 서로 연결된 네트워크를 통해 복잡계 모델을 공동으로 추정하는 과정을 분석한다. 에이전트는 자신의 최신 관측값과 이웃들의 모델 평균을 결합해 업데이트하며, 네트워크 구조는 ER 및 BA 유형을 사용한다. 특정 에이전트가 다른 오류 확률을 가질 때, 그 에이전트의 연결 차수가 전체 추정 정확도에 미치는 영향이 선형(또는 적합도 기반에서는 초선형)으로 나타난다. 또한 커뮤니티 구조를 도입해 오류 확률이 높은 에이전트 간 연결이 다른 커뮤니티의 성능 저하를 초래함을 확인한다.
상세 분석
이 논문은 다중 에이전트 시스템이 관측 오류를 포함한 불완전한 데이터로부터 복잡계의 구조적 모델을 어떻게 학습하는지를 수학적·시뮬레이션적으로 탐구한다. 핵심 가정은 각 에이전트 i가 시점 t에 관측한 네트워크 인접 행렬 A_i(t)와 이웃 집합 N_i의 모델 평균 M̄_i(t)= (1/|N_i|)∑_{j∈N_i}M_j(t) 를 가중합하여 새로운 추정 M_i(t+1)= (1-α)·A_i(t)+α·M̄_i(t) 로 업데이트한다는 점이다. 여기서 α는 이웃 정보에 대한 신뢰도를 나타내는 파라미터이며, 논문에서는 α=0.5로 고정하였다. 관측 오류는 각 에이전트마다 독립적인 확률 ε_i 로 정의되며, 실제 인접 행렬 A*와의 차이를 Hamming distance 형태로 측정한다.
네트워크 토폴로지는 무작위 Erdős–Rényi (ER)와 스케일프리 Barabási–Albert (BA) 두 종류를 사용해 실험하였다. ER에서는 평균 차수 ⟨k⟩을 조절해 연결 밀도를 변화시켰고, BA에서는 초기 연결 수 m을 바꾸어 허브 노드의 존재 정도를 조절하였다. 주요 실험에서는 전체 에이전트가 동일한 오류 확률 ε를 가질 때 평균 추정 오차 Ē(t)= (1/N)∑_i d(M_i(t),A*) 가 시간에 따라 지수적으로 감소하고, 최종 수렴값은 네트워크 평균 차수와 양의 상관관계를 보이는 것을 확인했다.
특수 상황으로, 하나의 에이전트 s가 다른 오류 확률 ε_s (ε_s>ε 혹은 ε_s<ε)를 가질 때, 그 에이전트의 차수 k_s가 전체 시스템의 평균 오차에 미치는 영향을 정량화하였다. 시뮬레이션 결과는 ΔĒ ≈ C·k_s·(ε_s-ε) 로, 차수가 클수록 영향이 선형적으로 확대됨을 보여준다. 여기서 C는 네트워크 유형과 α에 따라 달라지는 상수이다. 더욱 흥미로운 점은 차수를 적합도(fitness) 파라미터로 사용해 네트워크 성장 규칙에 반영할 경우, ΔĒ이 k_s^β (β>1) 형태의 초선형 관계를 나타내어, 허브 노드가 높은 오류를 가질 경우 전체 학습 품질이 급격히 악화된다는 점이다. 이는 실제 사회·경제 시스템에서 영향력 있는 전문가가 잘못된 정보를 제공할 경우 파급 효과가 크게 나타날 수 있음을 시사한다.
또한, 에이전트를 커뮤니티 구조(두 개 이상의 클러스터)로 구분하고, 특정 커뮤니티 내부에 오류 확률이 높은 에이전트들을 집중 배치한 경우를 분석하였다. 이때 커뮤니티 간 연결(edge) 비율을 p_cross 로 두고, 높은 오류 에이전트 간 내부 연결을 강화하면 (p_intra ↑) 다른 커뮤니티의 평균 오차가 유의하게 상승한다. 이는 오류가 집중된 서브그룹이 네트워크 전체에 “오염”을 전파하는 메커니즘을 보여준다. 분석을 통해 p_cross가 충분히 높을 경우(≈0.3 이상) 오류 전파가 완화되어 전체 시스템이 비교적 안정적인 수렴을 보인다.
수학적 해석 측면에서는 전체 시스템을 평균화된 동역학 방정식으로 근사하고, 고정점 분석을 통해 수렴값을 ε와 평균 차수 ⟨k⟩의 함수로 도출하였다. 특히, 특수 에이전트가 존재할 때는 평균 차수에 대한 가중 평균을 사용해 효과적인 오류 확률 ε_eff = ε + (k_s/N)·(ε_s-ε) 로 표현할 수 있다. 이 식은 시뮬레이션 결과와 정량적으로 일치한다.
결론적으로, 논문은 (1) 네트워크 토폴로지와 에이전트 간 상호작용이 관측 오류 하에서의 학습 효율을 결정한다, (2) 오류 확률이 다른 핵심 노드가 시스템 전체에 미치는 영향은 차수에 비례하거나 초선형으로 확대될 수 있다, (3) 커뮤니티 내부의 오류 집중은 다른 커뮤니티의 성능 저하를 야기한다는 세 가지 주요 통찰을 제공한다. 이러한 결과는 분산 센서 네트워크, 협업 필터링, 그리고 사회적 학습 모델 설계에 실질적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기