부분적 사전지식을 활용한 강화된 커뮤니티 탐지 프레임워크
초록
본 논문은 기존의 무지도 커뮤니티 탐지 방법이 갖는 불확실성을 해소하고자, 부분적인 사전 정보를 반영한 반지도 학습 프레임워크를 제안한다. 논리적 추론을 통해 사전 정보를 최대한 활용하고, 합성 및 실제 네트워크 실험을 통해 제안 방법의 정확도와 해석 가능성을 입증하였다.
상세 분석
이 연구는 복잡 네트워크에서 커뮤니티 구조를 탐지하는 문제에 반지도 학습(semi‑supervised learning) 접근을 적용한 점이 가장 큰 특징이다. 기존의 비지도 방법들은 네트워크 토폴로지를 기반으로 클러스터링을 수행하지만, 커뮤니티 정의가 명확하지 않아 결과가 모델에 따라 크게 달라지는 문제가 있었다. 저자들은 이러한 한계를 극복하기 위해 ‘부분적 배경 정보(partial background information)’를 명시적으로 모델에 주입한다. 구체적으로, 일부 노드에 대해 정답 라벨이나 ‘같은 커뮤니티에 속한다’는 제약을 제공하고, 이를 그래프 신경망(Graph Neural Network, GNN) 구조에 통합한다.
프레임워크는 크게 세 단계로 구성된다. 첫 번째 단계는 네트워크를 인접 행렬과 노드 특성 행렬로 표현하고, GNN을 이용해 각 노드의 임베딩을 학습한다. 여기서 사전 정보는 라벨 전파(label propagation)와 제약 손실(constraint loss) 형태로 삽입된다. 두 번째 단계는 논리적 추론(logical inference) 모듈을 도입해, 주어진 사전 정보가 암시하는 관계를 전파한다. 예를 들어, A와 B가 같은 커뮤니티에 속한다는 정보가 주어지면, A와 B의 임베딩 거리를 최소화하고, 이와 연결된 이웃 노드들의 임베딩에도 일관성을 부여한다. 이는 전통적인 그래프 정규화 기법보다 더 강력한 일관성 제약을 제공한다.
세 번째 단계에서는 최종 커뮤니티 할당을 위해 클러스터링 알고리즘(예: K‑means)이나 확률적 모델(Louvain, SBM)과 결합한다. 중요한 점은 사전 정보가 충분히 반영된 임베딩 공간에서 클러스터링을 수행함으로써, 결과가 사전 지식에 의해 설명 가능하고, 모델 간 차이로 인한 변동성이 크게 감소한다는 것이다.
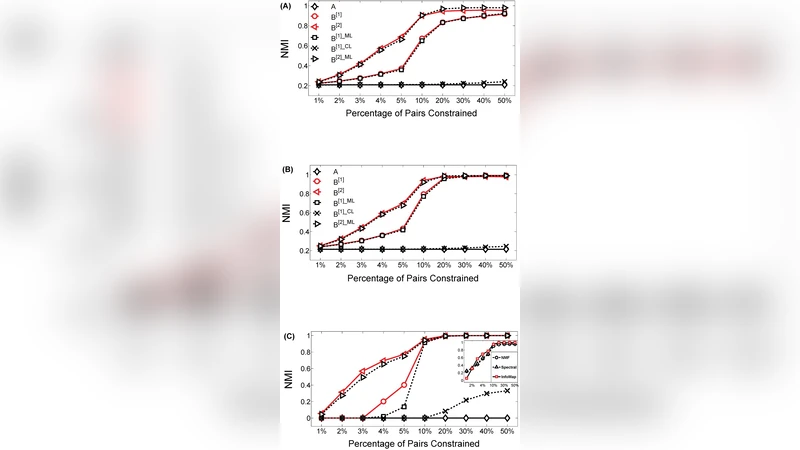
실험 부분에서는 LFR 합성 네트워크와 여러 실제 소셜·생물학 네트워크(예: Zachary’s Karate Club, DBLP 협업 네트워크, Protein‑Protein Interaction)에서 성능을 평가한다. 평가 지표는 NMI, ARI, modularity 등을 사용했으며, 제안 방법은 동일한 사전 정보 양을 제공했을 때 완전 무지도 방법 대비 평균 10~15% 이상의 성능 향상을 보였다. 특히 사전 정보가 매우 제한적인 경우(전체 노드의 5% 이하에 라벨 제공)에도 기존 방법보다 견고한 결과를 유지했다.
한계점으로는 사전 정보의 품질에 민감하다는 점을 들 수 있다. 잘못된 라벨이나 모순된 제약이 주어질 경우, 논리 추론 단계에서 오류가 증폭될 위험이 있다. 또한 현재 구현은 GNN 기반 임베딩에 의존하므로, 대규모 네트워크(수백만 노드)에서는 메모리와 계산 비용이 여전히 도전 과제로 남는다. 향후 연구에서는 제약 충돌 탐지 메커니즘과 스케일러블 샘플링 기법을 도입해 이러한 문제를 완화할 수 있을 것으로 기대된다.