정규화 최대 평균 차이를 통한 가설 검정의 새로운 접근
본 연구는 두 데이터 샘플이 서로 다른 분포에서 생성되었는지 판별하는 핵심 문제를 다룹니다. 기존의 최대 평균 차이(MMD) 방법을 정규화하여 RMMD라는 새로운 검정 통계량을 제안합니다. RMMD는 작은 샘플 크기에서도 검정력을 크게 향상시키며, 특히 다중 비교 시나리오에서 우수한 성능을 보입니다. EEG 데이터, MNIST, Covertype, Flare-Solar 등 다양한 데이터셋에서 탁월한 결과를 입증하였습니다.
저자: Somayeh Danafar, Paola M.V. Rancoita, Tobias Glasmachers
이 논문은 통계학과 머신러닝의 근본 문제인 두 표본 동질성 검정을 다루며, 커널 기반 방법의 검정력을 획기적으로 향상시킨 정규화 최대 평균 차이(RMMD) 방법을 소개합니다.
서론에서는 동질성 검정의 중요성과 기존 비모수적 방법인 MMD의 한계를 지적합니다. MMD는 고차원 특징을 포착할 수 있지만, 작은 샘플에서 검정력이 낮고, 다중 비교 시 교정된 유의수준 하에서 그 검정력이 더욱 약화되는 문제가 있습니다.
이론적 배경 섹션에서는 가설 검정의 기본 개념을 설명하고, MMD가 RKHS에서 두 분포의 평균 요소 간 거리로 정의되는 방식을 상세히 기술합니다. 또한, 다중 비교 문제와 이를 해결하기 위한 Dunn-Šidák 보정 방법을 소개하며, 이로 인한 검정력 감소 문제를 제기합니다.
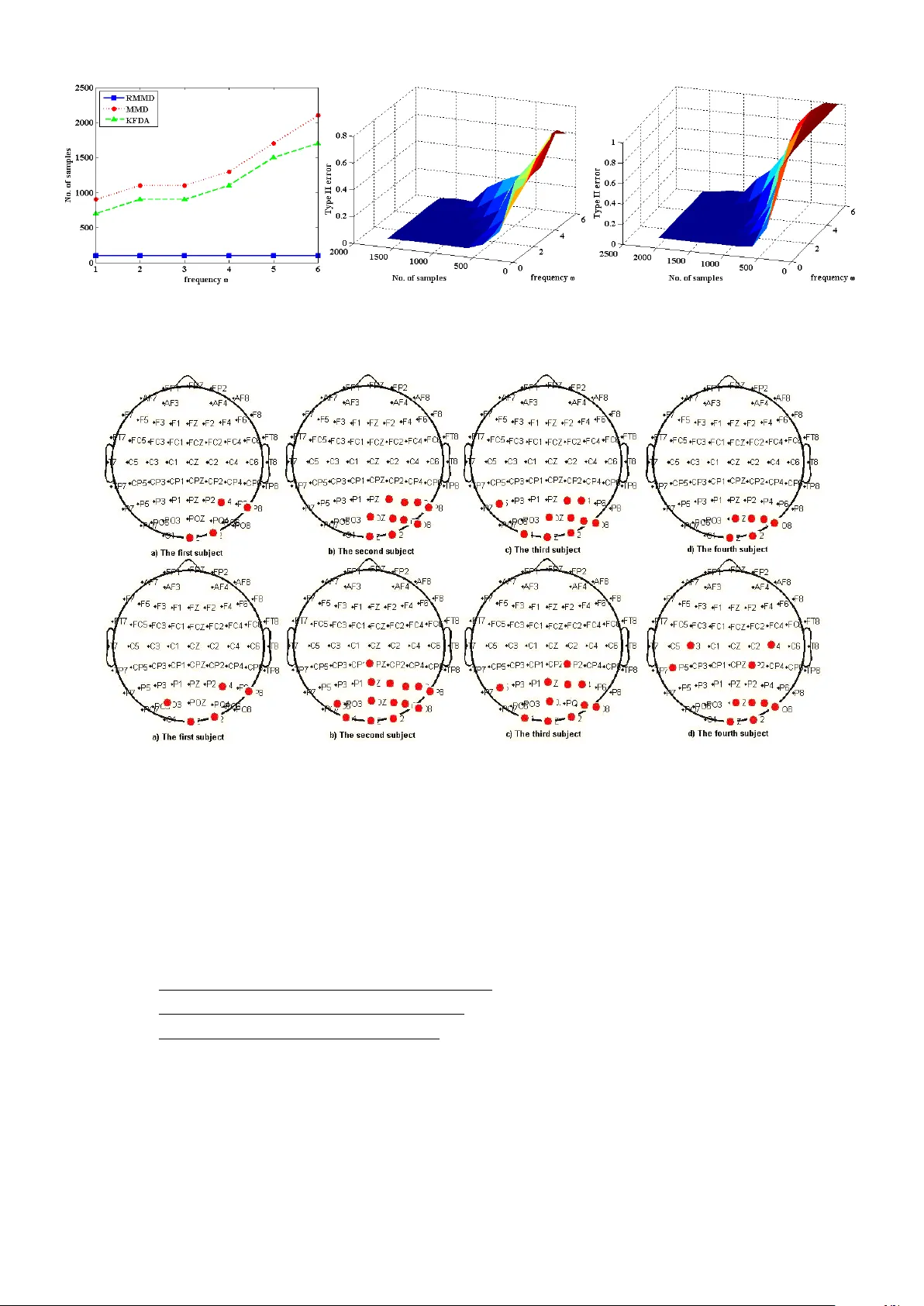
본 논문의 핵심인 RMMD는 MMD^2에서 각 분포의 평균 요소 노름 제곱에 정규화 상수 κ를 곱한 값을 뺀 것으로 정의됩니다. 저자들은 RMMD 검정 통계량이 귀무 가설(두 분포가 동일)과 대립 가설(두 분포가 다름) 모두에서 정규 분포로 수렴함을 증명합니다. 이는 귀무 가설 하에서 분포가 퇴화하는 MMD와 달리 정확한 유의성 판단을 가능하게 합니다. 특히, 검정력을 최대화하는 최적의 κ 값이 1임을 증명하여, 사용자 조정 없이도 최고 성능을 보장합니다.
RMMD를 MMD와 KFDA(Kernel Fisher Discriminant Analysis)와 비교합니다. KFDA는 within-distribution 공분산 연산자로 정규화하지만, 큰 샘플에서만 정규 분포에 수렴하며 검정력 수렴 속도가 느립니다. 반면 RMMD는 더 빠른 수렴 속도와 작은 샘플에서의 높은 검정력을 제공합니다. 또한, Bahadur 점근적 상대 효율성(ARE) 분석을 통해 RMMD가 동일한 검정력을 달성하는 데 필요한 샘플 크기가 MMD나 KFDA보다 훨씬 작음을 실험적으로 보여줍니다.
실험 섹션에서는 주기적 데이터, 가우시안 데이터와 같은 인공 데이터셋과 EEG, MNIST, Berkeley Covertype, Flare-Solar 같은 실제 벤치마크 데이터셋을 사용하여 RMMD의 성능을 검증합니다. 기존의 Kolmogorov-Smirnov(KS) 검정, Hall-Tajvidi 검정, MMD, KFDA와 비교했을 때, RMMD는 특히 샘플 크기가 작은 상황과 다중 비교 설정에서 월등한 검정력을 보였습니다. 이는 RMMD가 이론적 우수성뿐만 아니라 실제 응용에서도 효과적임을 입증합니다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기