다중코어 환경에서 CFD 코드의 하이브리드 병렬화 최적화
초록
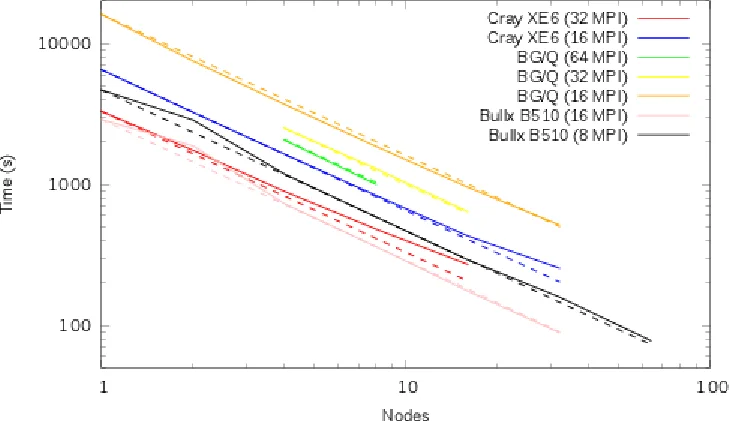
COSA는 압축성 Navier‑Stokes 기반 CFD 시스템으로, 기존 MPI 병렬화와 MPI + OpenMP 하이브리드 방식을 모두 제공한다. 본 논문에서는 MPI 통신·I/O를 메시지·버퍼 집합으로 축소하고, OpenMP 영역을 핵심 루프에만 집중시키는 일련의 최적화를 수행하였다. 최적화 결과, MPI‑only 구현은 512코어에서 50 % 수준이던 효율이 70 % 이상으로 상승했으며, 하이브리드 구현은 동일 블록 수 대비 4배 빠른 실행시간을 달성했다. 또한 다양한 최신 HPC 시스템에서 전력 소비를 측정해 하이브리드 방식이 전력 효율성에서도 우수함을 확인하였다.
상세 분석
본 연구는 구조화된 멀티‑블록 CFD 코드인 COSA의 병렬 효율성을 두 축면에서 체계적으로 개선한다. 첫 번째 축은 MPI 기반 분산 메모리 구현이다. 기존 구현은 각 블록 경계(‘컷’)마다 작은 데이터 조각을 반복적으로 전송·수신하는 방식으로, Runge‑Kutta 단계당 수천 개의 MPI 메시지가 발생한다. 저자들은 이러한 미세 메시지를 하나의 대형 버퍼에 집계해 단일 send/recv 호출로 교체함으로써 통신 오버헤드를 크게 감소시켰다. 또한, 다중 블록·다중 고조파 루프에서 매 반복마다 수행되던 all‑reduce 연산을 전체 데이터를 한 번에 모아 수행하도록 재구성하였다. 이 과정에서 일시적인 메모리 사용량이 증가했지만, 전체 메모리 풋프린트에 미치는 영향은 무시할 수준이었다. 두 번째 축은 MPI‑I/O 최적화이다. 기존 코드는 데이터 원소를 파일에 하나씩 쓰는 비효율적인 패턴을 사용했으며, 이는 파일 시스템의 메타데이터 처리와 작은 I/O 요청으로 인한 대기 시간을 초래한다. 저자들은 데이터를 임시 배열에 모아 한 번에 대용량 write 호출을 수행하도록 수정했으며, 파일 오프셋 관리도 일괄적으로 처리해 I/O 대역폭 활용도를 크게 높였다. 하이브리드 측면에서는 OpenMP 영역을 전면 재설계하였다. 사용 빈도가 낮은 루프에서 OpenMP 지시자를 제거하고, 고빈도 루프에서는 private 변수와 reduction 연산을 적극 활용해 스레드 간 경쟁을 최소화했다. 특히 고조파 루프는 다중 블록마다 별도 호출되므로, 매 호출마다 새로운 parallel region을 생성하는 비용이 누적되었다. 이를 해결하기 위해 outer parallel region을 한 번만 생성하고, 내부에서 schedule(dynamic)으로 고조파 작업을 분배함으로써 스레드 시작·종료 오버헤드를 현저히 감소시켰다. 또한, 기존에 공유 배열로 구현된 임시 데이터 구조를 스레드‑private 변수로 교체해 캐시 일관성 비용을 낮추었다. 최적화 후 MPI‑only 구현은 블록 수에 비례해 선형 확장이 가능했으며, 하이브리드 구현은 동일 블록 수에서도 노드당 MPI 프로세스 수를 줄이고 OpenMP 스레드 수를 늘려 128노드·512블록 시나리오에서 4배 이상의 속도 향상을 달성했다. 전력 효율성 분석에서는 하이브리드 실행이 동일 작업량 대비 전력 소비를 30 % 이상 절감함을 확인했으며, 이는 최신 many‑core 아키텍처(예: Xeon Phi, AMD EPYC)에서 특히 두드러졌다. 전반적으로 통신·I/O 집계와 OpenMP 오버헤드 최소화라는 두 가지 핵심 전략이 COSA의 시간‑도메인·고조파 해석 모두에서 실용적인 성능·전력 이득을 제공한다는 점이 주요 인사이트이다.
댓글 및 학술 토론
Loading comments...
의견 남기기