유전 알고리즘을 활용한 영상 음악 매칭 시스템
초록
**
본 논문은 영상의 움직임과 음악의 음량 변화를 추출한 뒤, 유전 알고리즘을 이용해 오디오 클립을 자동으로 절단·조합·배치함으로써 영상에 적합한 사운드트랙을 생성하는 방법을 제안한다. 사용자는 가중치를 조정해 적합도 함수를 맞춤 설정할 수 있으며, 실험 결과는 움직임이 큰 장면에 강렬한 음악을, 정적인 장면에 부드러운 음악을 매칭하는 것이 가능함을 보여준다.
**
상세 분석
**
이 연구는 멀티미디어 편집에서 가장 직관적이면서도 주관적인 과제인 ‘음악‑영상 매칭’을 자동화하려는 시도로, 두 가지 핵심 기술을 결합한다. 첫 번째는 특징 추출 단계로, 영상에서는 프레임 차분을 통해 평균 움직임과 씬 컷을 500 ms 블록 단위로 계산한다. 이 방법은 빠른 움직임과 정적인 구간을 명확히 구분할 수 있어, 인간이 직관적으로 연관 짓는 ‘액션‑볼륨’ 관계를 수치화한다. 두 번째는 오디오 분석으로, 10 ms 샘플에 FFT를 적용해 10개의 옥타브 밴드 평균을 구하고, 역시 500 ms 블록으로 평균화한다. 여기서 음량 변화와 주파수 변동을 기준으로 음악의 구조적 변곡점을 탐지한다.
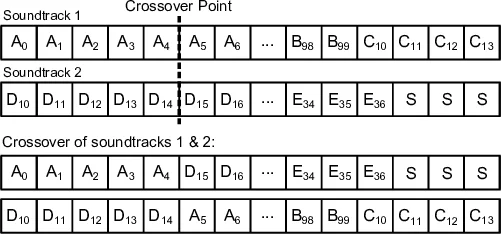
두 특징 집합을 기반으로 유전 알고리즘이 작동한다. 각 500 ms 구간을 하나의 유전자로 보고, 전체 영상 길이에 맞춰 연속된 유전자를 배열한 것이 염색체이다. 초기 집단은 무작위로 선택된 오디오 클립과 침묵 구간을 조합해 생성되며, 이는 ‘다양성 확보’를 위한 설계이다. 선택 연산은 토너먼트 방식을 사용하고, 교차 연산은 시간 축에서 임의의 교차점을 잡아 두 부모 염색체의 앞·뒤 부분을 교환한다. 변이 연산은 네 가지 형태(위치 이동, 교체, 길이 조정, 삭제)를 제공해 해답 공간을 넓힌다.
적합도 함수는 가중치가 부여된 다중 기준으로 구성된다. (1) 영상 움직임과 오디오 레벨의 상관관계(양의 상관을 최대화), (2) 오디오 조각의 평균 길이와 개수(과도한 전환 방지), (3) 침묵 비율(과다 침묵 억제), (4) 씬 경계와 오디오 시작점 정렬(전환 부자연성 최소화)이다. 사용자는 이 가중치를 조정해 ‘드라마틱’, ‘리듬감’, ‘조용함’ 등 선호 스타일을 반영할 수 있다.
실험에서는 70 초 길이의 영화 클립과 두 곡(멜로디 중심의 Bittersweet와 강렬한 Fuel)을 사용했다. 시스템은 자동으로 Bittersweet의 저음역 구간을 정적인 장면에, Fuel의 고음·드럼 구간을 액션 씬에 매칭했으며, 동일 파라미터에서도 서로 다른 해답을 다수 생성했다. 전환 부자연성은 페이드 인·아웃으로 완화했지만, 여전히 주관적 평가가 필요함을 인정한다.
본 논문의 주요 기여는 (① 영상·음악의 저차원 특징을 실시간으로 추출, (② 유전 알고리즘을 통한 전역 최적화와 다중 해답 제공, (③ 사용자 정의 적합도 함수로 창의적 제어 가능)이다. 한계점으로는 움직임·음량 외의 감정, 가사, 장르 등 고차원 의미를 반영하지 못한다는 점과, 전환 품질을 완전히 자동화하기엔 아직 부족하다는 점을 들 수 있다. 향후 연구에서는 상호작용 적합도(사용자 피드백 기반 실시간 평가)와 다중 감각 특징(색상, 조명, 템포, 하모니) 확장을 통해 보다 풍부하고 예술적인 매칭을 목표로 한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기