희귀질환 진단을 위한 특화 검색 엔진 FindZebra
초록
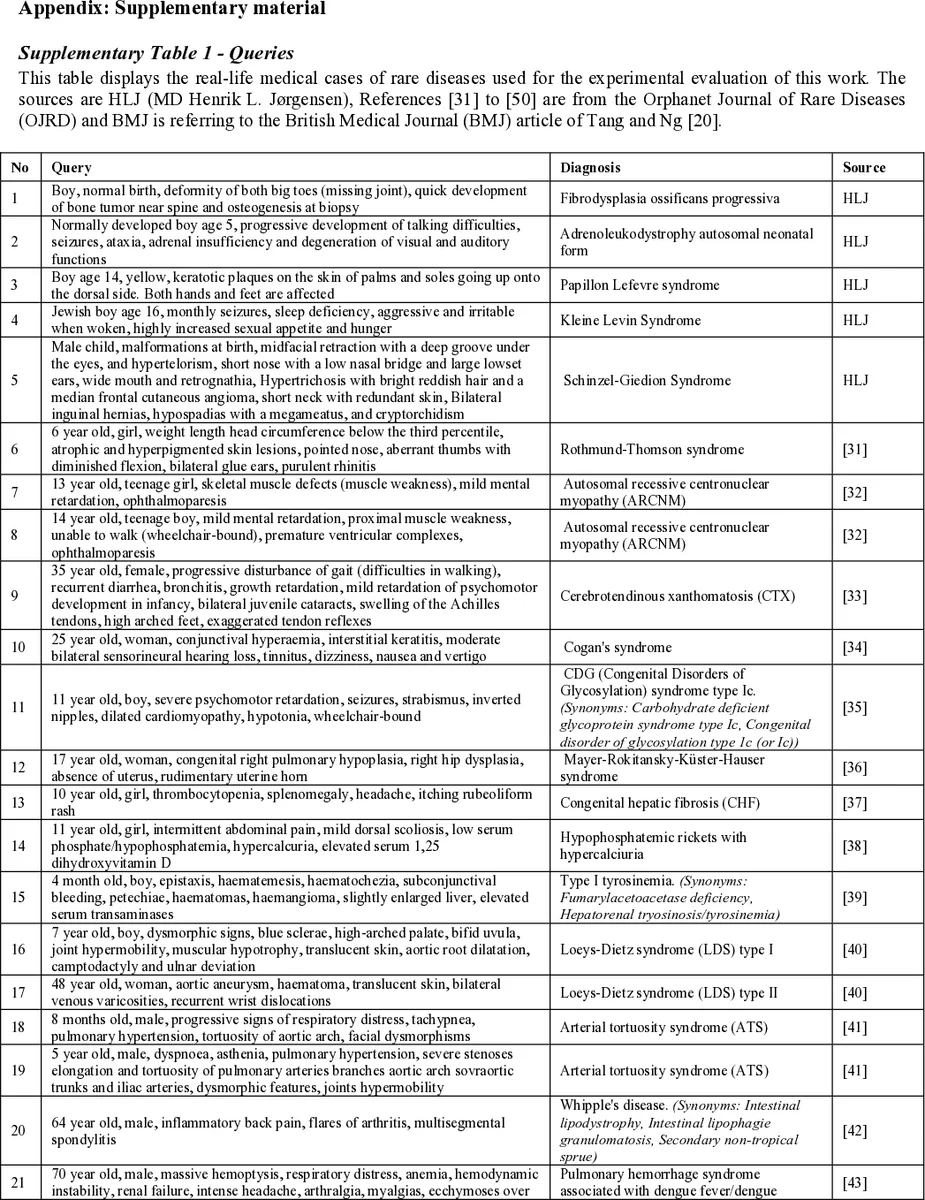
본 논문은 희귀질환 진단을 지원하기 위해 구축한 전문 검색 엔진 FindZebra를 소개하고, 56건의 실제 임상 사례를 이용해 Google 검색 및 PubMed과 비교 평가한다. Curated된 의학 데이터와 오픈소스 검색 기술을 활용해 질의‑문서 매칭을 최적화했으며, UMLS·HPO 기반의 온톨로지 확장을 통해 결과 표시 방식을 다양화했다. 실험 결과 FindZebra가 기존 일반 검색 엔진보다 높은 정밀도·재현율을 보이며, 진단 품질 향상에 기여함을 확인하였다.
상세 분석
FindZebra는 희귀질환이라는 특수 도메인에 맞춰 설계된 수직 검색 엔진으로, 일반 웹 검색 엔진이 갖는 “짧은 쿼리 최적화”, “링크 기반 순위”, “저빈도 용어 삭제”와 같은 구조적 한계를 의도적으로 회피한다. 논문에서는 56개의 실제 임상 사례를 수집해 증상 리스트 형태의 복합 질의를 구성하고, 이를 기반으로 정밀도(P@k), 평균 정밀도(MAP), nDCG 등 정보 검색 분야 표준 지표를 적용해 성능을 정량화하였다. FindZebra의 인덱스는 Orphanet, OMIM, POSSUMweb 등 신뢰할 수 있는 공개 데이터베이스를 크롤링해 구축했으며, 텍스트 전처리 단계에서 의학 용어 표준화와 어간 추출을 수행해 용어 독립성 가정을 최소화하였다. 검색 엔진 핵심은 Apache Lucene 기반의 역색인 구조이며, 질의 확장을 위해 UMLS 메타데이터와 HPO(인간 표현형 온톨로지)를 매핑해 증상 간 의미적 연관성을 반영한다. 결과 표시에서는 원문 스니펫 외에 해당 질환의 ICD‑10 코드, 관련 논문 링크 등을 함께 제공해 임상의가 빠르게 판단할 수 있도록 설계되었다. 비교 실험에서는 Google Custom Search Engine을 동일한 데이터셋에 적용했지만, Google의 기본 알고리즘이 여전히 페이지랭크와 클릭 로그에 의존해 노이즈가 많은 결과를 반환한다는 점이 드러났다. PubMed은 주로 논문 메타데이터에 기반해 검색하지만, 질의가 증상 리스트 형태일 때는 대부분의 문서가 검색에서 제외되는 현상이 관찰되었다. 반면 FindZebra는 질의‑문서 매칭을 전면 재구성함으로써 상위 10개 결과에서 평균 70% 이상의 정확도를 달성했으며, 특히 증상이 희귀하거나 복합적인 경우에 두드러진 성능 향상을 보였다. 이러한 결과는 도메인 특화 인덱스와 의료 온톨로지 활용이 진단 지원 검색에서 핵심적인 역할을 함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기