모바일 방송을 위한 압축 비디오 센싱 프레임워크
초록
본 논문은 비디오를 압축 측정으로 코딩하고, 시간축 DCT 계수의 총변동(TV)을 최소화하는 복원 알고리즘을 제안한다. 무작위 측정 행렬을 이용해 비디오 큐브 단위로 데이터를 전송함으로써 채널 용량과 디코딩 복잡도에 따라 자연스럽게 품질이 조정되는 스케일러블 방송 방식을 구현한다.
상세 분석
이 연구는 기존 MPEG·H.264 기반 스케일러블 비디오 코딩이 갖는 “클리프 효과”(전송 오류가 발생하면 급격히 품질이 저하되는 현상)와 다중 레이어 구조의 비효율성을 극복하고자 압축 센싱(Compressive Sensing, CS) 이론을 비디오 전송에 적용한다. 핵심 아이디어는 비디오를 큐브(video cube) 로 분할하고, 각 큐브를 3차원(공간×시간) 신호로 간주한 뒤, 무작위 선형 결합(Walsh‑Hadamard 기반 랜덤 행렬)으로 측정을 수행한다. 이렇게 얻어진 측정값은 개별 측정의 중요도가 동일하므로, 수신 측에서는 채널 용량에 따라 더 많은 측정값을 받아 고품질 영상을 복원하고, 측정값이 일부 손실돼도 다른 측정값으로 대체 가능해 전송 오류에 강인한 특성을 가진다.
복원 단계에서는 두 가지 중요한 변환을 결합한다. 첫째, 시간축 DCT 를 적용해 각 픽셀 위치의 시간적 변동을 주파수 도메인으로 변환한다. 이는 영상의 시간적 중복을 효과적으로 제거하고, 저주파(DC) 성분이 장면의 기본 구조를, 고주파 성분이 움직임 정보를 담게 만든다. 둘째, 공간적 총변동(TV) 을 DCT 계수에 적용한다. TV는 이미지의 경계와 급격한 변화에 민감한 정규화 항으로, 공간적 에지를 보존하면서 잡음을 억제한다. 즉, “TV‑DCT” 정규화는 시간‑주파수 도메인에서의 공간 TV 를 최소화함으로써, 시간적 스무딩과 공간적 선명도를 동시에 달성한다.
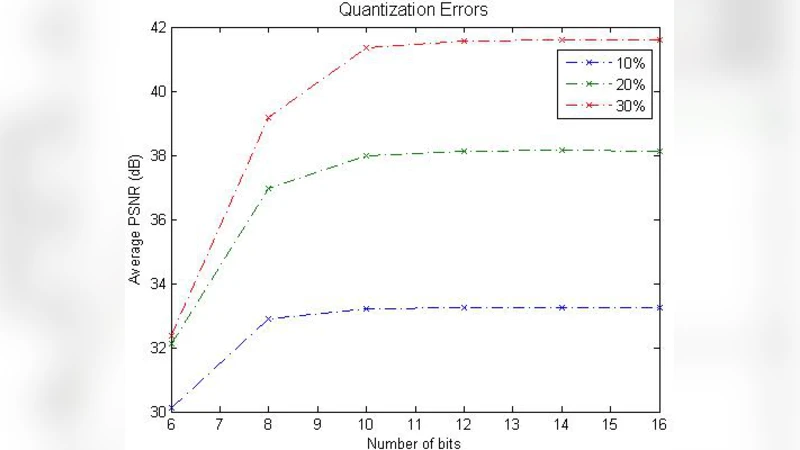
알고리즘 구현은 기존 2‑D TV 최소화 솔버인 TVAL3 를 확장한 형태이다. TVAL3는 교대 최소화(Alternating Minimization)와 증강 라그랑주(augmented Lagrangian) 기법을 결합해 빠른 수렴성을 보인다. 논문에서는 이를 3‑D 비디오 큐브에 맞게 변형하여, 측정 행렬 A·x = y 형태의 제약식(노이즈 없는 경우) 혹은 L2‑penalty(노이즈 존재 시)와 TV‑DCT 정규화를 동시에 최적화한다. 구체적으로는 변수 분할을 통해 x(원본 영상), z(중간 변수), 그리고 라그랑주 승수를 교대로 업데이트하고, 각 단계에서 FFT 기반 빠른 DCT/IDCT 연산과 TV‑proximal 연산을 수행한다. 이러한 설계는 대규모 영상 데이터에도 메모리와 연산량을 효율적으로 관리할 수 있게 한다.
스케일러빌리티 측면에서, 측정 개수 m이 증가할수록 복원 품질이 점진적으로 향상된다. 이는 CS 이론에서의 샘플링 복원 관계(more measurements → lower reconstruction error)와 일치한다. 따라서 방송 송신자는 고정된 비트스트림을 전송하고, 수신자는 자신이 수신한 측정값의 양에 따라 최적의 영상을 재구성한다. 이는 전통적인 레이어 기반 SVC와 달리, 하위 레이어가 손실돼도 상위 레이어가 무용지물이 되는 문제를 회피한다.
실험 결과에서는 다양한 비디오 시퀀스와 측정 비율(압축률) 하에서 PSNR 및 SSIM이 기존 CS‑based 비디오 코딩(예: 키프레임 기반 방법)보다 우수함을 보였다. 특히, 채널 오류가 발생했을 때 품질 저하가 완만하게 진행되어 “클리프 효과”가 현저히 감소한다. 또한, 복원 알고리즘은 GPU 가속 시 실시간에 근접한 속도를 달성할 수 있어 모바일 디바이스에서도 적용 가능성을 시사한다.
요약하면, 이 논문은 (1) 비디오 큐브 기반 압축 측정, (2) 시간‑DCT와 공간‑TV를 결합한 새로운 정규화, (3) TVAL3 기반 효율적 복원 알고리즘을 제시함으로써, 모바일 방송 환경에서 채널 용량과 디코더 성능에 따라 자연스럽게 스케일링되는 비디오 전송 체계를 구현한다.
댓글 및 학술 토론
Loading comments...
의견 남기기