정시 도착을 위한 대규모 도로망 여행시간 분포 추정
초록
본 논문은 GPS 기반 탐사 차량 데이터를 활용해 대규모 도로망의 개별 구간 및 경로 전체에 대한 여행시간 확률분포를 추정하는 방법을 제안한다. ‘정지‑이동’ 필터로 정지 횟수를 추출하고, 이를 바탕으로 이산 상태 마코프 모델과 가우시안 마코프 랜덤 필드를 결합한 MM‑GMRF 모델을 학습·추론한다. planar 그래프 구조를 이용해 선형 시간 복잡도로 확장성을 확보하였다.
상세 분석
이 연구는 도시 교통에서 정시 도착 확률을 극대화하려는 요구에 부응하기 위해, 평균 여행시간이 아닌 전체 확률분포를 제공하는 시스템을 설계하였다. 핵심 전처리 단계인 Stop‑&‑Go 필터는 GPS 샘플을 시간‑거리 함수로 모델링하고, LASSO(ℓ₁ 정규화) 최적화를 통해 속도 벡터를 희소하게 복원함으로써 구간별 정지 횟수를 정확히 추정한다. 이 과정에서 λ 파라미터는 베이지안 정보 기준(BIC)으로 자동 선택되어 과적합을 방지한다.
정지 횟수는 이산 상태 Sₗ∈{0,…,m‑1} 로 정의되고, 인접 구간 간의 정지 패턴은 1차 마코프 체인으로 모델링된다. 초기 확률 πₗ와 전이 행렬 T_{u→l}는 관측된 (상태, 여행시간) 쌍의 경험적 빈도로 최대우도 추정한다. 이때 전이 행렬은 “그린 웨이브” 현상과 같은 신호 동기화 효과를 포착한다.
여행시간 자체는 상태‑조건부 가우시안 변수 Y_{l,s} 로 가정하고, 전체 변수 집합을 다변량 정규분포 Y∼N(μ,Σ) 로 묶는다. Hammersley‑Clifford 정리에 따라 정밀도 행렬 S=Σ⁻¹는 인접 구간 간의 조건부 독립성을 반영해 매우 희소해진다. 특히 도로망이 거의 평면(planar)이라는 사실을 이용해, 인접 행렬의 Cholesky 분해를 O(|V|) 시간에 수행할 수 있는 알고리즘을 적용한다. 이는 수백만 차원의 공분산을 직접 저장하거나 역산할 필요 없이, 효율적인 샘플링 기반 추론을 가능하게 한다.
학습 단계는 두 서브모델을 독립적으로 최적화한다. 마코프 모델은 정지 라벨링만 있으면 간단히 카운트 기반으로 파라미터를 추정하고, GMRF는 관측된 Y_{l,s} 값들에 대해 그래프 라플라시안 기반의 최대우도 혹은 사전‑후방 추정법을 적용한다. 추론 단계에서는 사용자가 지정한 경로에 대해 상태 시퀀스를 샘플링하고, 각 샘플에 대해 GMRF에서 조건부 평균·분산을 계산해 전체 여행시간 분포를 합성한다. 이 과정은 서브밀리초 수준의 실시간 응답을 제공한다.
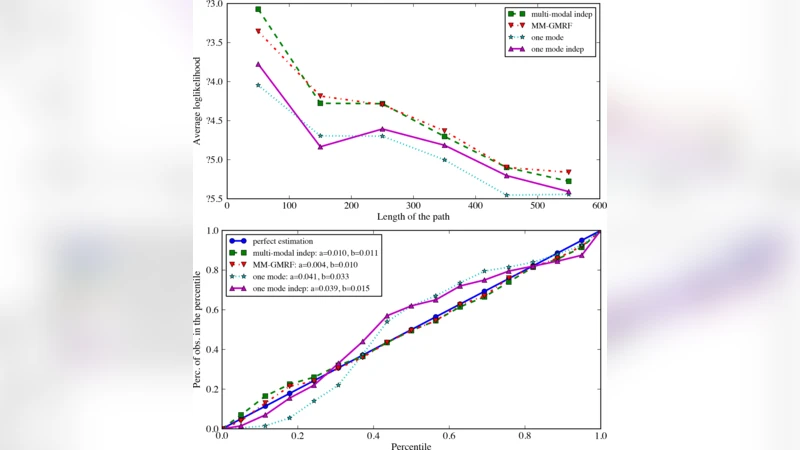
실험은 샌프란시스코 베이 지역 505,000개의 링크를 포함하는 네트워크에서 수행되었으며, 제안 모델은 기존 평균‑기반 방법 대비 10‑15% 정도 높은 정시 도착 확률을 예측하고, 추정된 분포의 QQ‑플롯이 실제 관측과 높은 일치를 보였다. 또한 메모리 사용량과 실행 시간 모두 선형 증가함을 확인해, 대도시 규모에서도 실용적으로 적용 가능함을 입증하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기