문학 사조를 복합 네트워크로 탐지하는 새로운 방법
초록
1590년부터 1922년까지 출판된 77권의 책을 단어 연결망으로 변환하고, 네트워크 지표들을 다변량 분석하여 여섯 개의 군집을 도출했다. 평균 최단 경로 길이의 비대칭성이 문체 구분에 가장 큰 영향을 미치며, 시간에 따라 평균 최단 경로 길이는 증가하고 단어 빈도 파워‑법칙 지수는 감소한다는 경향을 발견했다.
상세 분석
본 연구는 텍스트를 복합 네트워크로 모델링하는 전형적인 파이프라인을 따랐다. 먼저 Gutenberg 프로젝트에서 수집한 77권의 고전 문헌을 전처리했는데, 구두점과 의미가 약한 기능어(관사·전치사 등)를 제거하고, MXPOST 태거를 이용해 어간 추출(lemmatization)하였다. 이렇게 정제된 토큰들을 순차적으로 연결해 방향성 있는 단어‑단어 네트워크를 구축했으며, 각 네트워크는 단어를 정점, 인접 단어쌍을 간선으로 표현한다.
네트워크 특성 추출은 11가지 지표를 포함한다. 가장 기본적인 정점 수 N은 어휘 규모를 나타내며, 정점 차수 분포는 Zipf 법칙에 따라 파워‑법칙 형태(p_k ∝ k^−γ)로 피팅해 지수 γ를 추정한다. 또한 차수 상관관계(assortativity Γ)와 클러스터링 계수 C, 가중 평균·표준편차·제3모멘트 등 다양한 통계량을 계산했다. 특히 평균 최단 경로 길이 l_i를 모든 정점에 대해 구하고, 그 평균 h_l, 표준편차 Δl, 가중 평균 h_l^w, 그리고 비대칭성(제3모멘트 ς(l))을 구해 텍스트 전반의 구조적 복잡성을 정량화했다.
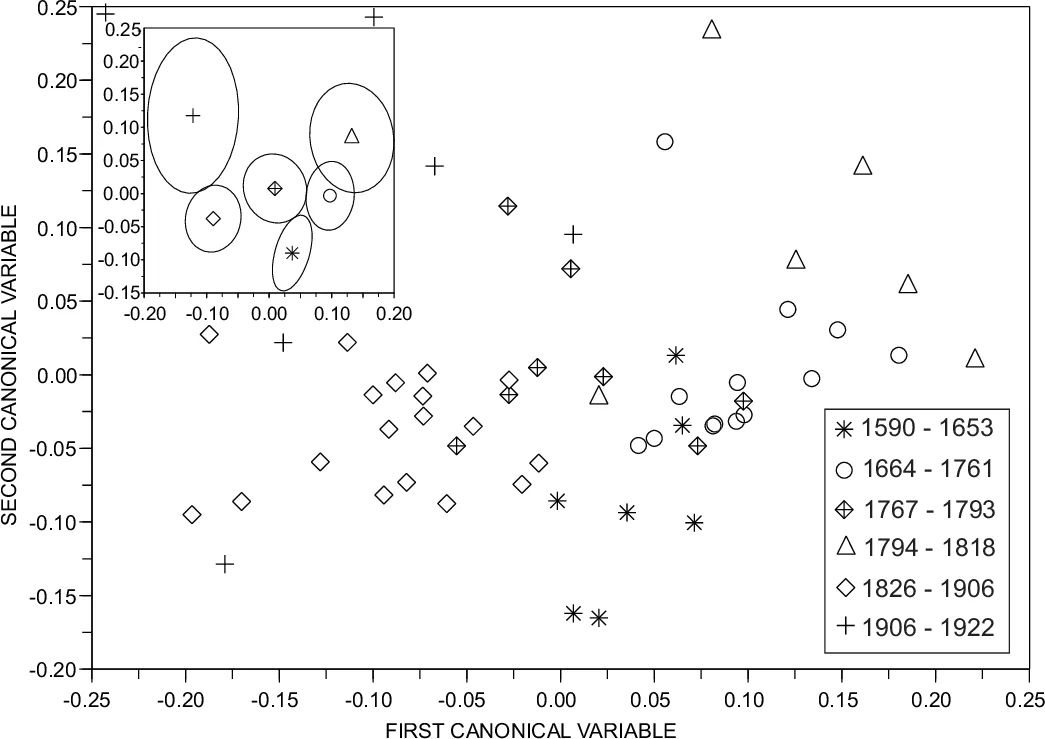
다변량 분석 단계에서는 Canonical Variate Analysis(CVA)와 Principal Component Analysis(PCA)를 활용해 시각화했으며, 실험적으로 실루엣 지수(SWC)와 Dunn 지수를 이용해 군집 수와 경계 위치를 최적화했다. 최종적으로 6개의 군집이 도출되었으며, 각 군집은 1590‑1653, 1664‑1761, 1767‑1793, 1794‑1818, 1826‑1906, 1906‑1922라는 연대 구간과 일치한다. 이 구간들은 기존 문학사에서 엘리자베스 시대, 계몽주의·네오클래시시즘, 고딕, 리얼리즘·내추럴리즘, 모더니즘 등과 대응한다.
특징 중요도 분석 결과, 평균 최단 경로 길이의 비대칭성 ς(l)과 어휘 규모 N이 군집 구분에 가장 크게 기여했으며, 클러스터링 계수 C와 그 가중 평균 C^w도 두 번째로 중요한 요인으로 나타났다. 시간 흐름에 따라 h_l이 점진적으로 증가하는데, 이는 문장의 구문적 복잡도가 높아짐을 의미한다. 반면 파워‑법칙 지수 γ는 감소하여 단어 빈도 분포가 보다 균등해짐을 보여준다. 이러한 변화는 작가들이 이전 시대의 스타일에 반발하거나 새로운 표현 방식을 모색하는 문화적·사회적 요인과도 연관될 수 있다. 부록 A의 기하학적 반대(opposition) 분석은 인접 군집 간의 벡터 차이가 크게 나타나, 급격한 스타일 전환이 프랑스 혁명 등 역사적 사건과 맞물려 있음을 시사한다.
전반적으로 복합 네트워크 지표와 다변량 군집 분석을 결합한 방법론은 문학 사조를 정량적으로 구분하고, 언어적·문화적 변천을 시계열적으로 추적하는 데 유용함을 입증한다. 또한 제시된 접근법은 텍스트의 다른 측면(예: 감성, 주제, 저자 식별)에도 확장 가능하다.
댓글 및 학술 토론
Loading comments...
의견 남기기