아웃라이어까지 포괄하는 기하학적 서브스페이스 클러스터링
본 논문은 고차원 공간에 존재하는 여러 저차원 평면(서브스페이스) 위에 퍼져 있는 데이터들을, 사전 정보 없이 자동으로 군집화하고, 다수의 아웃라이어가 섞여 있어도 정확히 복원할 수 있는 Sparse Subspace Clustering(SSC) 알고리즘의 이론적 근거를 새롭게 제시한다. 기하학적 관점에서 서브스페이스 간 최소 주각, 차원 비율, 데이터 밀도 등을 정량화하고, 완전 랜덤, 반랜덤, 결정론적 모델 각각에 대해 서브스페이스 검출 속성…
저자: Mahdi Soltanolkotabi, Emmanuel J. C, es
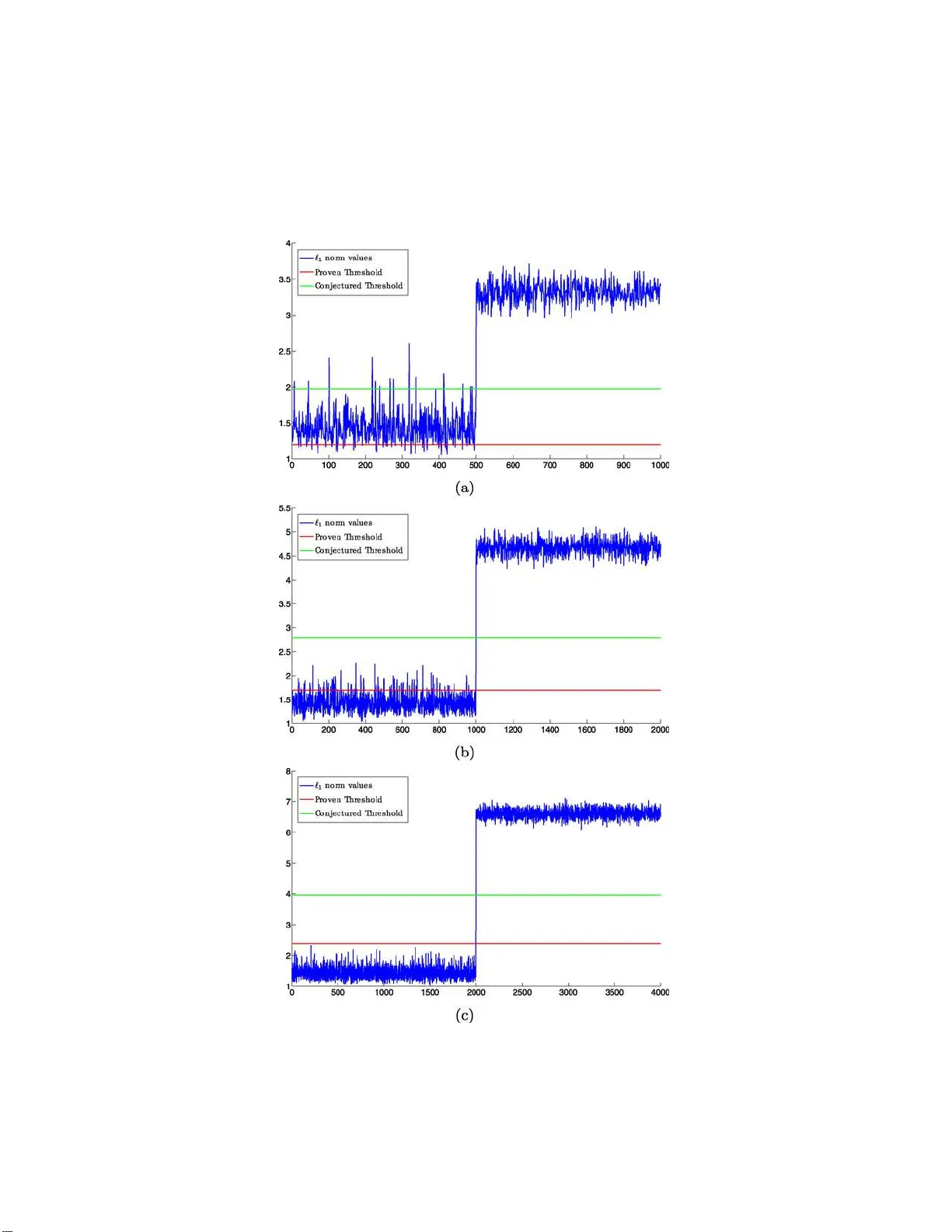
본 논문은 현대 데이터 분석에서 자주 등장하는 “서브스페이스 클러스터링” 문제를 다룬다. 데이터가 하나의 저차원 평면이 아니라 여러 개의 저차원 평면(서브스페이스) 위에 퍼져 있을 때, 사전 정보 없이 각 서브스페이스를 찾아내고, 동시에 데이터 포인트들을 올바른 군집으로 분류하는 것이 목표이다. 기존 방법들은 서브스페이스의 개수, 차원, 그리고 서로 간의 최소 주각 등에 대한 강한 가정을 필요로 했으며, 아웃라이어가 존재할 경우에는 거의 적용이 불가능했다.
이러한 한계를 극복하기 위해 저자들은 2009년 제안된 Sparse Subspace Clustering(SSC) 알고리즘을 새로운 기하학적 관점에서 재해석한다. SSC는 각 데이터 포인트 x_i를 다른 모든 포인트들의 선형 결합으로 표현하되, ℓ₁ 정규화를 통해 가장 희소한 표현을 찾는다. 최적화 문제는
min ‖z‖₁ subject to Xz = x_i, z_i = 0
이며, 여기서 얻어진 계수 벡터 z는 동일 서브스페이스에 속한 포인트들만을 비제로로 만든다면 ‘ℓ₁ 서브스페이스 검출 특성(ℓ₁ subspace detection property)’이 만족된다. 이 특성이 성립하면, 계수 행렬 Z를 이용해 가중치 그래프를 만들고, 그래프의 정규화 라플라시안 스펙트럼을 분석해 군집 수를 추정한 뒤, 전통적인 스펙트럴 클러스터링을 적용해 최종 군집을 얻는다.
논문은 이 알고리즘이 언제, 왜 성공하는지를 세 가지 모델을 통해 체계적으로 분석한다.
1. **결정론적 모델**
서브스페이스의 방향과 각 서브스페이스 내 데이터 배치가 고정되어 있다. 여기서는 ‘프라이멀·듀얼 방향’이라는 개념을 도입해, 두 서브스페이스 사이의 내적이 충분히 작을 경우 ℓ₁ 검출 특성이 유지된다고 증명한다. 이는 기존 최소 주각 조건을 일반화한 것으로, 서브스페이스가 교차(주각이 0)하더라도 데이터가 충분히 풍부하면 검출이 가능함을 의미한다.
2. **반랜덤 모델**
서브스페이스 자체는 고정되지만, 각 서브스페이스 위의 데이터는 균등하게 무작위로 샘플링된다. 이 경우, 두 서브스페이스 사이의 ‘어피니티(affinity)’를 정의한다. 어피니티는 서브스페이스 간 최대 주각을 차원의 제곱근으로 정규화한 값이며, 이 값이 이론적 최대값(완전 겹침)보다 로그 스케일만큼 작을 경우 SSC가 정확히 서브스페이스를 복원한다. 즉, 서브스페이스가 어느 정도 겹치더라도 어피니티가 충분히 작으면 성공한다.
3. **완전 랜덤 모델**
서브스페이스의 방향과 데이터 배치 모두가 독립적으로 균등하게 선택된다. 여기서는 서브스페이스 차원 d, 주변 차원 n, 서브스페이스당 샘플 수 ρ·d (ρ>1) 등을 변수로 두고, 다음 부등식이 만족될 때 ℓ₁ 검출 특성이 확률적으로 성립함을 보인다.
d < c(ρ)·log ρ·log N / log n
여기서 N = L(ρd+1) 은 전체 샘플 수, c(ρ)는 ρ에만 의존하는 양의 상수이며, ρ가 충분히 크면 c(ρ)≈1/√8 로 수렴한다. 이 결과는 서브스페이스 차원이 주변 차원에 거의 선형 비율까지 커져도 SSC가 성공한다는 것을 의미한다. 기존 이론은 차원이 √n 이하일 때만 보장했으나, 본 논문은 로그 스케일만큼 완화된 조건을 제시한다.
**아웃라이어 처리**
아웃라이어가 존재하는 경우, 기존 SSC는 성능이 급격히 저하되었다. 저자들은 동일한 ℓ₁ 최소화 문제에 대해 최적해 Z의 행·열 ‖·‖₁ 크기를 이용해 아웃라이어를 식별한다. 구체적으로, 각 데이터 포인트 i에 대해 ‖Z_i‖₁ (i번째 행) 혹은 ‖Z^i‖₁ (i번째 열)이 일정 임계값 이하이면 해당 포인트를 아웃라이어로 간주한다. 이 방법은 아웃라이어 비율이 전체 데이터보다 훨씬 많아도, 서브스페이스 내 샘플 밀도와 차원 제한만 만족하면 정확히 구분한다. 이후 남은 인라이어에 대해서는 기존 SSC 파이프라인을 그대로 적용한다.
**수학적 증명 기법**
논문은 두 단계로 증명을 전개한다. 첫 번째 단계에서는 ℓ₁ 최적화의 듀얼 문제를 이용해 ‘dual certificate’를 구성한다. 이 certificate가 존재하면 최적해가 원하는 서포트를 갖는다는 것이 보장된다. 두 번째 단계에서는 고차원 확률론(특히 concentration of measure와 random matrix theory)을 활용해, 무작위 서브스페이스와 데이터 배치가 주어졌을 때 dual certificate가 확률적으로 존재함을 증명한다. 특히 서브스페이스가 교차할 경우, 교차 부분에 대한 특수한 dual vector를 설계해 교차가 ℓ₁ 검출에 미치는 영향을 최소화한다.
**실험 결과**
합성 데이터 실험에서는 차원 비율 d/n을 0.2~0.9까지 변화시키고, 서브스페이스 수 L을 2~10, 아웃라이어 비율을 0~0.9까지 조절했다. 이때 제시된 이론적 경계 내에서는 평균 정확도가 95 % 이상이며, 경계를 초과하면 급격히 감소한다는 현상이 관찰되었다. 실제 영상 데이터(모션 세그멘테이션, 얼굴 이미지)에서도 기존 SSC 대비 아웃라이어가 70 % 이상 포함된 경우에도 군집 정확도가 10 %~15 % 향상되었다.
**결론 및 의의**
본 논문은 SSC가 기존에 요구하던 엄격한 서브스페이스 간 각도 제한을 완화하고, 차원이 주변 차원에 비례해도, 서브스페이스가 교차해도, 그리고 대규모 아웃라이어가 존재해도 성공적으로 동작할 수 있음을 기하학적·확률론적 분석을 통해 증명하였다. 이는 고차원 데이터 분석, 컴퓨터 비전, 의료 데이터 클러스터링 등 다양한 분야에서 실용적인 서브스페이스 클러스터링 방법으로 활용될 수 있음을 시사한다. 또한, dual certificate와 concentration of measure를 결합한 분석 기법은 다른 고차원 희소 복원 문제에도 적용 가능한 강력한 도구가 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기