희소 텍스트를 밀집 표현으로 변환하는 dCoT 기법
dCoT는 단어 빈도가 낮은 sBoW 벡터를 자주 등장하는 프로토타입 단어 집합으로 매핑해, 고차원 희소 표현을 저차원 밀집 특징으로 변환한다. 무작위 단어 제거를 수식적으로 마진화하여 닫힌 형태의 선형 변환을 얻으며, tanh 비선형 함수를 적용해 이진형태의 특징을 만든다. 실험 결과, Reuters와 DMOZ 데이터셋에서 기존 TF‑IDF, LSI, SDA 등에 비해 분류 정확도가 크게 향상되고 학습 속도도 현저히 빠르다.
저자: Zhixiang (Eddie) Xu, Minmin Chen, Kilian Q. Weinberger
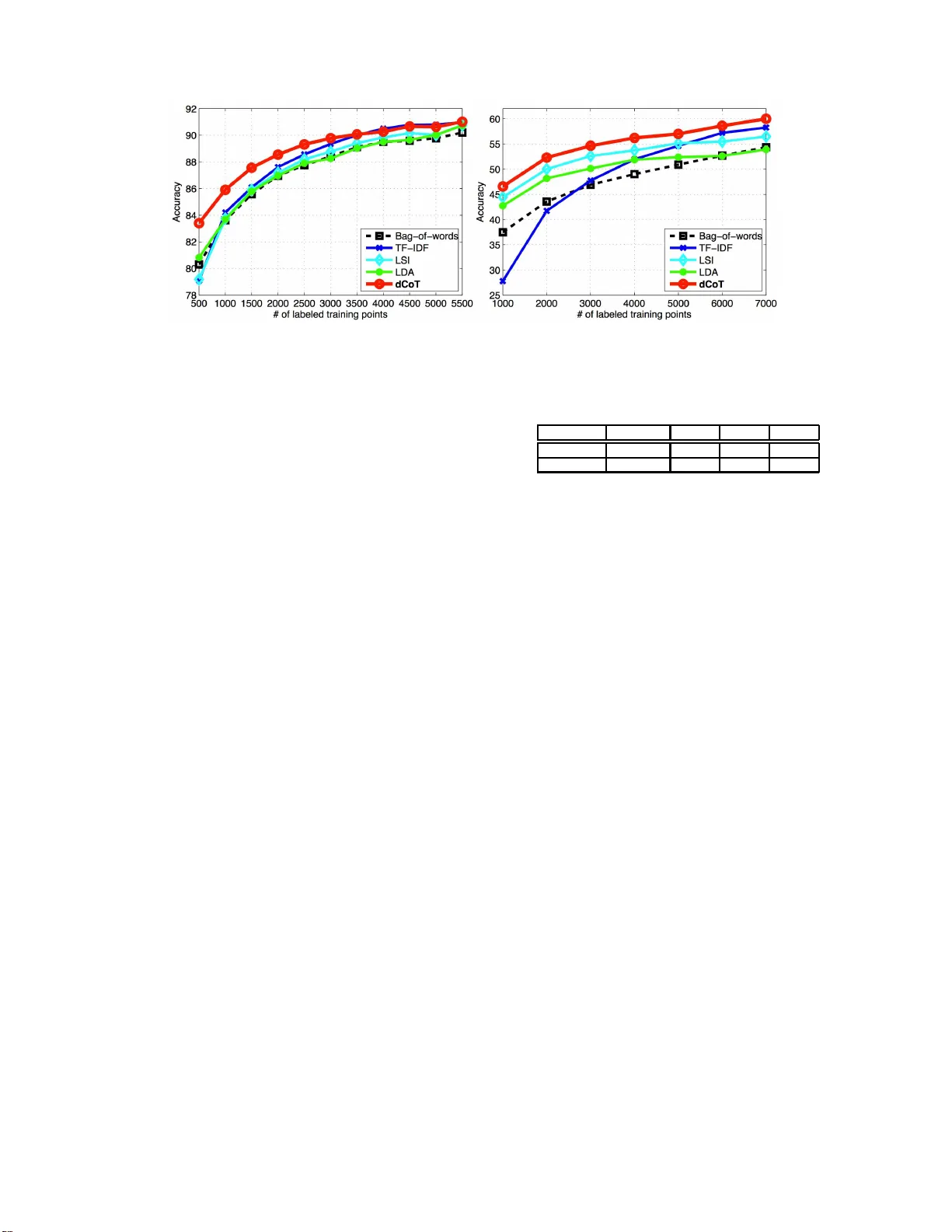
본 논문은 텍스트 문서를 표현하는 전통적인 희소 Bag‑of‑Words(sBoW)와 그 변형인 TF‑IDF가 가지고 있는 근본적인 문제점을 지적한다. 어휘 규모가 수십만에 달함에도 불구하고 실제 문서에서 사용되는 단어는 몇 천 개에 불과하고, 이로 인해 대부분의 특징이 훈련 데이터에 거의 등장하지 않아 과적합이 발생한다. 특히 라벨이 제한된 상황이나 짧은 문서(이메일, 초록 등)에서는 이러한 희소성이 더욱 심각해진다. 이러한 한계를 극복하고자 저자들은 Dense Cohort of Terms(dCoT)라는 새로운 비지도 학습 알고리즘을 제안한다.
dCoT는 전체 어휘 D에서 가장 빈번한 r개의 단어를 프로토타입 집합 P로 정의한다. 이 프로토타입은 동의어 군집을 대표하는 역할을 하며, 일반적으로 r는 d에 비해 매우 작다(예: d≈50000, r≈500). 목표는 모든 단어를 이 프로토타입으로 “번역”하는 선형 매핑 W∈ℝ^{r×d}를 학습하는 것이다. 이를 위해 입력 문서 x∈ℝ^{d}에 대해 각 차원을 독립적으로 일정 확률 p로 0(삭제)으로 만든 손상된 버전 ˆx를 만든다. 손상된 입력 ˆx를 이용해 원본 문서의 프로토타입 부분 ¯x=
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기