클러스터 기반 변분 근사와 정밀한 그래프 구조 선택
** 본 논문은 전통적인 평균장(mean‑field) 근사를 확장하여, 클러스터 잠재함수(cluster potentials)로 구성된 근사 분포를 도입한다. 일반화된 평균장 방정식을 유도하고, 이를 통해 무방향 그래프, 유향 비순환 그래프, 그리고 정밀한 정점-분리 트리(junction tree) 사이의 연속적인 트레이드오프를 제공한다. 또한 근사 분포의 그래프 구조를 사전에 단순화하는 규칙을 제시하며, 기존 변분 방법들과의 관계를 명확히 …
저자: Wim Wiegerinck
**
본 연구는 변분 추정(variational inference) 분야에서 오랫동안 사용되어 온 평균장(mean‑field) 근사의 한계를 극복하고자 하는 시도에서 출발한다. 평균장은 모든 변수들을 서로 독립적인 팩터로 분해함으로써 계산 복잡도를 크게 낮추지만, 변수 간의 복잡한 상호작용을 무시하게 된다. 반면, 정점‑분리 트리(junction tree) 알고리즘은 정확한 추론을 제공하지만, 클리크 크기가 커질수록 계산 비용이 급격히 증가한다. 저자는 이 두 극단 사이에 **연속적인 스펙트럼**을 제공하는 새로운 변분 근사 프레임워크를 제안한다.
### 1. 클러스터 기반 근사의 정의
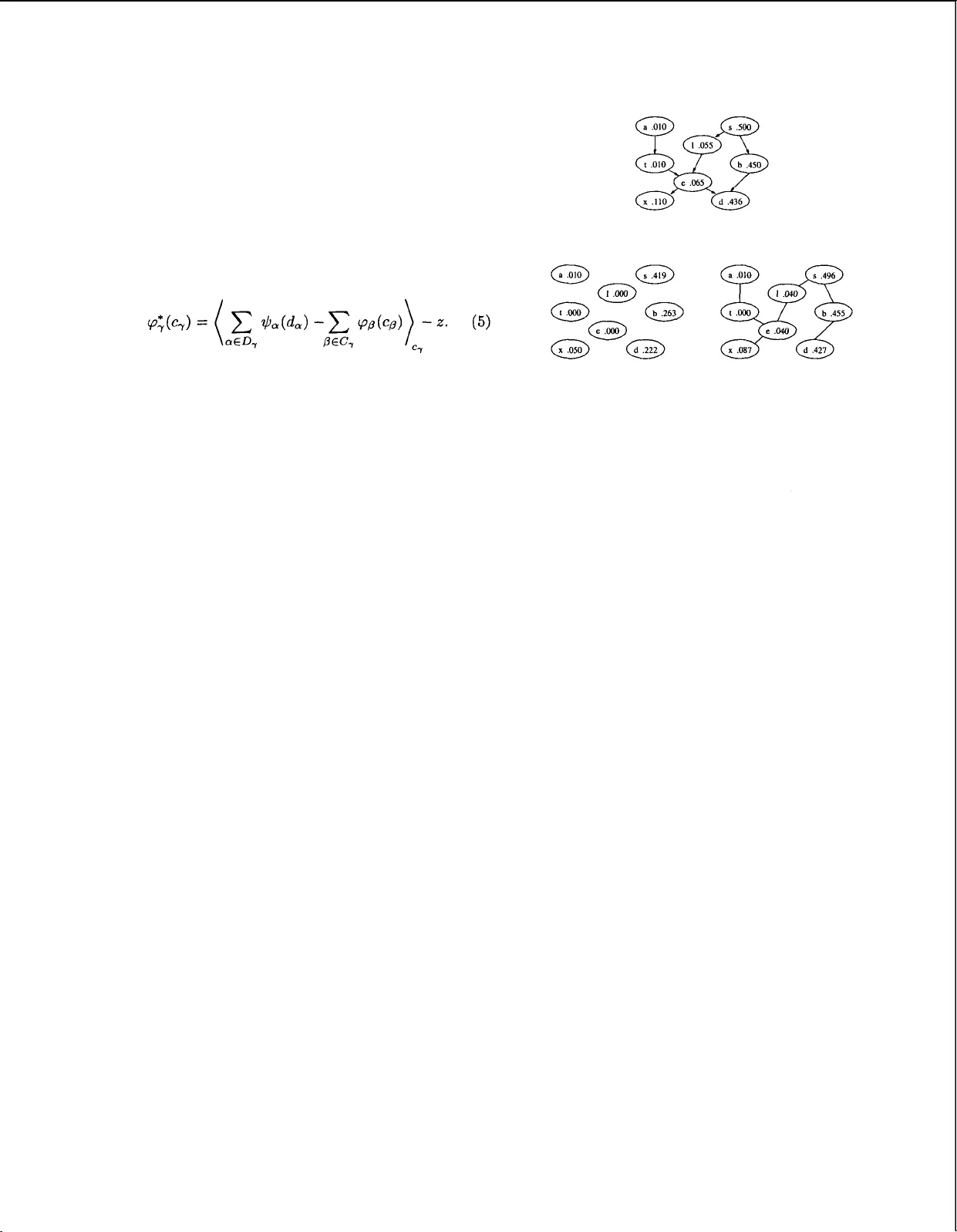
근사분포 q(x)를 변수 집합 X={X₁,…,X_N}에 대해 **클러스터** C₁,…,C_K 로 나눈다. 각 클러스터 C_k는 변수들의 부분집합이며, 클러스터 간에는 겹침(overlap)이 허용된다. 근사분포는
q(x)=∏_{k=1}^{K} φ_{C_k}(x_{C_k}) / Z
형태로 정의된다. 여기서 φ_{C_k}는 클러스터 C_k에 대한 잠재함수이며, Z는 정규화 상수이다. 클러스터가 단일 변수일 경우는 전통적인 평균장, 클러스터가 정점‑분리 트리의 최대 클리크와 동일하면 정확한 트리 알고리즘과 일치한다.
### 2. 일반화 평균장 방정식 유도
목표는 KL(q‖p)=∫q(x)log
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기