베이즈 네트워크 구조 추정: 순서 기반 MCMC와 특징 후방 확률 계산
** 본 논문은 제한된 데이터 상황에서 베이즈 네트워크 구조의 개별 특징(예: 변수 간 직접 인과 관계)의 사후 확률을 정확히 추정하는 새로운 방법을 제안한다. 고정된 변수 순서에 대해 모든 가능한 DAG를 효율적으로 합산하는 알고리즘을 개발하고, 이를 기반으로 순서 공간을 탐색하는 MCMC를 수행한다. 순서 공간은 구조 공간보다 작고 매끄러워 샘플링 효율이 크게 향상된다. 실험 결과는 기존 구조‑기반 MCMC와 부트스트랩 방법에 비해 높은…
저자: Nir Friedman, Daphne Koller
**
베이즈 네트워크는 변수들 간의 인과 관계를 DAG 형태로 모델링함으로써 복잡한 확률 구조를 직관적으로 표현한다. 전통적인 베이즈 네트워크 학습은 두 단계로 이루어진다. 첫 번째는 데이터 D에 대한 사후 확률이 가장 큰 구조, 즉 MAP 모델을 찾는 것이고, 두 번째는 그 구조를 기반으로 변수 간 직접적인 인과 관계를 해석한다. 그러나 데이터가 충분히 많지 않은 현실적인 상황에서는 MAP 모델 하나에 의존하는 것이 위험하다. 여러 구조가 비슷한 사후 확률을 가질 수 있기 때문에, 특정 엣지(예: X → Y)가 실제로 존재할 확률을 정확히 추정하려면 **모든 가능한 구조**에 대한 사후 확률을 합산해야 한다. 이를 **특징(Feature) 사후 확률**이라고 부른다.
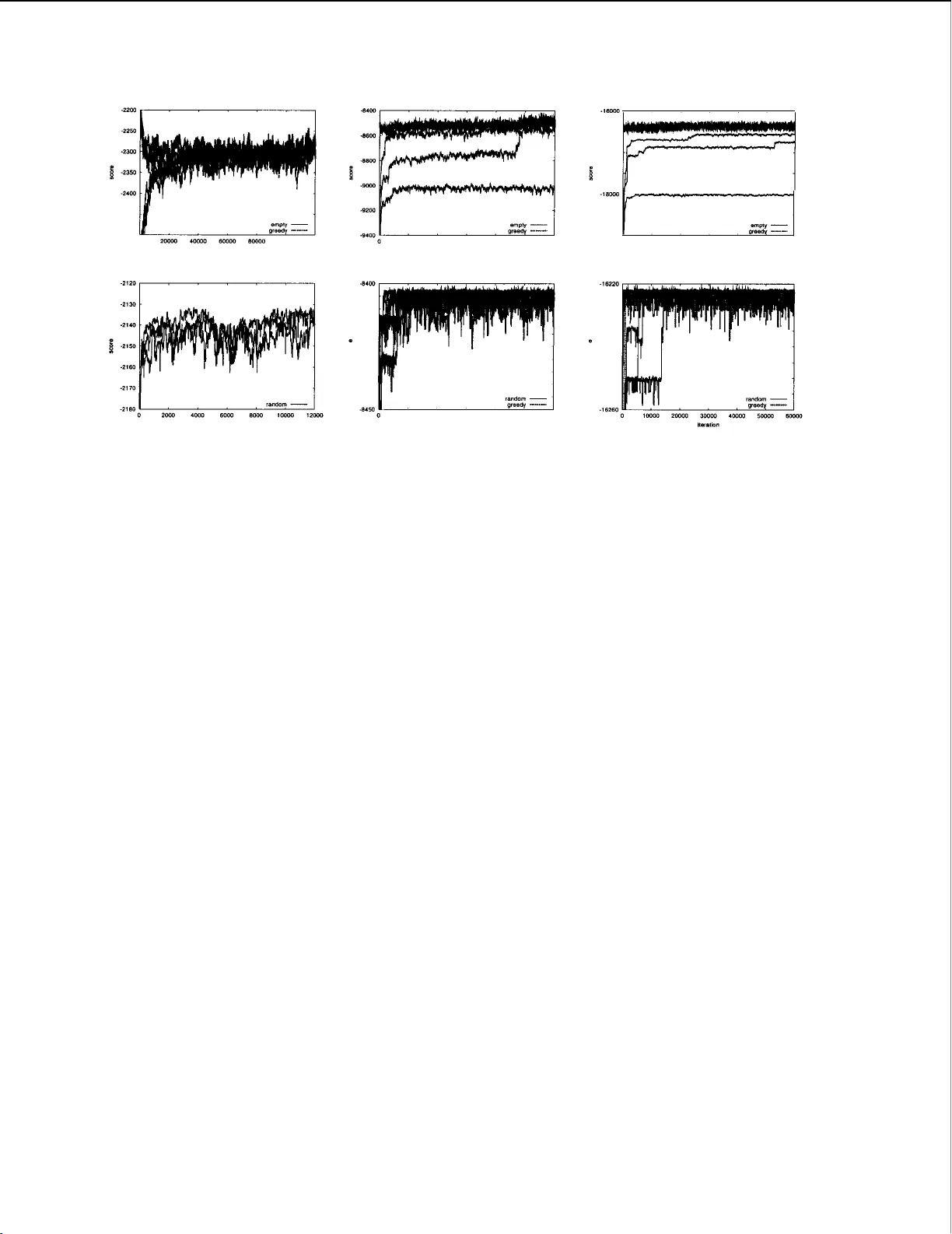
하지만 DAG의 수는 n!·2^{n(n‑1)/2} 로 급격히 증가하므로, 직접적인 합산은 계산적으로 불가능하다. 기존 연구들은 두 가지 방향으로 접근한다. (1) **구조‑기반 MCMC**: 구조 공간을 직접 탐색하면서 샘플을 수집하고, 샘플에 포함된 엣지들의 빈도로 특징 사후 확률을 근사한다. (2) **부트스트랩**: 데이터 자체를 재표본화하여 여러 MAP 모델을 얻고, 그 빈도로 특징을 평가한다. 두 방법 모두 샘플링 효율이 낮거나, 근사 오차가 크게 발생한다.
본 논문은 이러한 한계를 극복하기 위해 **순서(Variable Ordering) 기반 접근**을 제안한다. 순서는 변수들을 위에서 아래로 정렬한 순열이며, 주어진 순서가 정해지면 DAG는 각 변수 i가 그 앞에 있는 변수들 중 일부를 부모로 선택하는 형태로 제한된다. 즉, 순서가 고정되면 각 변수의 부모 집합 선택은 서로 독립적인 조합 문제로 변환된다. 이때 가능한 부모 집합은 2^{i‑1} 개이며, 전체 DAG 수는 ∏_{i=1}^{n} 2^{i‑1}=2^{n(n‑1)/2} 로 순서가 고정된 경우에도 여전히 많지만, **동적 프로그래밍(DP)** 을 이용하면 전체 구조에 대한 **마진 가능도**와 **특정 특징(예: 엣지 X→Y)의 마진**을 정확히 계산할 수 있다.
### 1. 순서별 합산 알고리즘
- **점수 함수**: BDeu 혹은 BGe와 같은 베이즈 점수를 사용한다. 각 변수 i와 가능한 부모 집합 Pa(i) 에 대해 점수 s(i, Pa(i)) 를 사전 계산한다.
- **DP 테이블**: 순서 π = (π_1,…,π_n) 에 대해, DP
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기