대규모 시계열 베이즈망 실시간 추론 기술
초록
본 논문은 실시간 스트리밍 환경에서 수백~수천 개 변수로 구성된 동적 베이즈망을 정확히 추론하기 위한 새로운 알고리즘을 제시한다. 인터페이스 노드 수를 최소화하고 정적·동적 노드를 구분해 결합 확률을 효율적으로 분해함으로써 메모리와 CPU 사용량을 고정된 수준으로 유지한다.
상세 분석
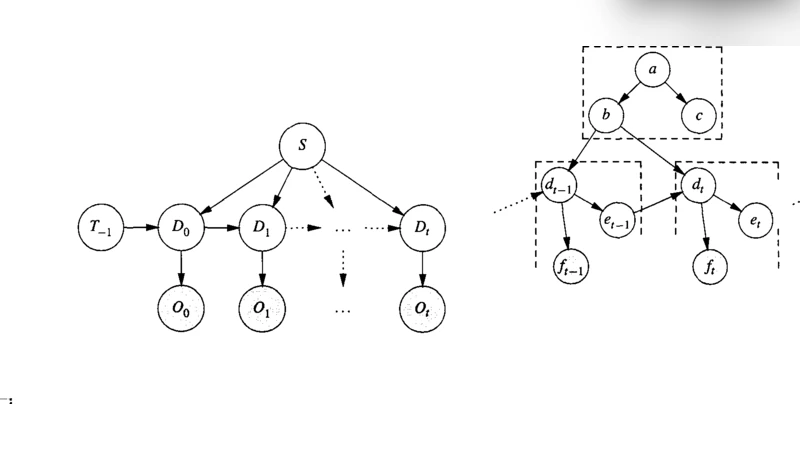
이 연구는 기존 동적 베이즈망(DBN) 추론 기법이 시간 슬라이스당 수백 개 이상의 변수에 대해 선형 혹은 지수적인 복잡도를 보이며 실시간 적용이 불가능하다는 점을 출발점으로 삼는다. 저자들은 복잡도 병목이 “인터페이스 노드”(시간 t와 t+1 사이를 연결하는 변수) 수에 의존한다는 사실을 정량화하고, 이를 최소화하는 두 가지 전략을 제안한다. 첫 번째는 정적 노드와 동적 노드를 명확히 구분하는 것이다. 정적 노드는 시간에 따라 변하지 않으며, 이들의 확률분포는 한 번만 계산하면 된다. 반면 동적 노드는 매 시간 단계마다 업데이트가 필요하지만, 이들을 가능한 한 적은 수의 인터페이스 노드에만 국한시켜 전체 그래프의 차원을 축소한다. 두 번째 전략은 인터페이스 노드들의 결합 분포를 팩터화하는 것이다. 저자들은 인터페이스 노드 집합을 조건부 독립성에 기반해 여러 작은 클러스터로 나누고, 각각의 클러스터에 대해 별도 확률식(잠재 변수 포함)을 도출한다. 이렇게 하면 전체 결합 분포를 직접 다루는 비용이 급격히 감소한다.
알고리즘 구현 단계에서는 정적 표현(static representation) 개념을 도입한다. 전체 DBN을 시간에 독립적인 정적 그래프와 시간에 따라 변하는 동적 서브그래프로 분리한 뒤, 기호적 확률 추론(symbolic probabilistic inference, SPI) 엔진을 이용해 정적 그래프에 대한 분석적 확률식을 도출한다. 이 식은 두 부분으로 나뉜다. (1) 시간마다 변하지 않는 상수 부분은 사전에 완전 계산(pre‑computation)되어 메모리에 저장된다. (2) 매 시간 단계마다 입력 데이터에 따라 값이 바뀌는 변수만을 포함하는 동적 부분은 절차적 코드로 컴파일된다. 컴파일된 코드는 고정된 메모리 할당량과 일정한 연산량을 보장하므로, 실시간 시스템에서 예측 가능한 지연시간을 제공한다.
복잡도 분석 결과, 인터페이스 노드 수가 k라 할 때 전체 연산량은 O(2^k)에서 O(k·2^{k_s}) 로 감소한다. 여기서 k_s는 팩터화 후 각 클러스터에 남은 인터페이스 노드 수이며, 일반적인 실세계 모델에서는 k_s ≪ k 이다. 따라서 메모리 사용량도 동일하게 지수적 폭발을 억제한다. 또한, 정적 부분을 미리 계산함으로써 매 시간 단계마다 수행되는 연산은 주로 행렬‑벡터 곱셈 수준에 머물러, 현대 CPU/GPU 환경에서 수십 마이크로초 이내에 결과를 도출할 수 있다.
이러한 설계는 실시간 제약을 갖는 감시·제어, 금융 트레이딩, 의료 모니터링 등 다양한 스트리밍 애플리케이션에 직접 적용 가능하도록 만든다. 특히, 모델 크기가 수천 변수에 달하더라도 인터페이스 노드와 정적/동적 구분을 통해 일정한 리소스 사용량을 유지한다는 점이 가장 큰 혁신이다.