위키를 위한 확장 XDB 프로토타입
초록
본 논문은 NASA가 개발한 오픈소스 데이터베이스 아키텍처 XDB를 기업 환경의 위키 시스템에 적용한 프로토타입을 소개한다. DARC 프로토콜을 확장하여 MediaWiki의 16가지 태그에 대한 텍스트 검색 기능을 구현했으며, 향후 전체 위키 마크업 및 다른 위키 방언까지 지원할 계획이다.
상세 분석
XDB는 NASA가 과학·공학 분야의 이기종·분산 정보 자원을 통합하기 위해 만든 경량형 데이터베이스 프레임워크이다. 핵심은 Data Access and Retrieval Composition(DARC) 프로토콜로, 이는 문서의 구조적 메타데이터가 없어도 컨텍스트 기반 검색을 가능하게 한다. 기존 XDB는 주로 파일 시스템, 데이터베이스, 웹 서비스 등 다양한 소스에 대한 일관된 조회 인터페이스를 제공했으며, 스키마가 필요 없는 자유 형식 데이터를 다루는 데 강점을 가지고 있다.
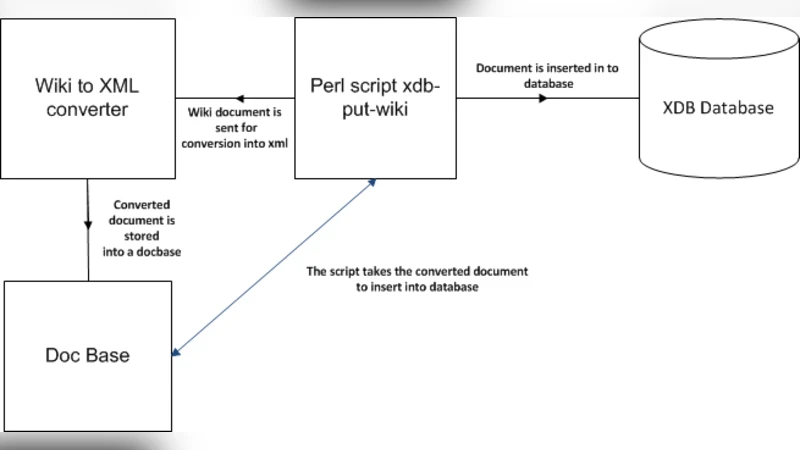
이 논문에서 제안한 확장 XDB는 위키와 같은 협업 플랫폼에 적용하기 위해 두 가지 주요 기술적 변화를 도입한다. 첫째, DARC 요청에 위키 페이지의 마크업을 파싱하는 모듈을 추가하여, 사용자가 지정한 태그(예: {{Infobox}}, ==섹션== 등)를 기준으로 텍스트를 추출하고 색인한다. 둘째, MediaWiki 방언에 특화된 16개의 태그를 사전 정의하고, 각 태그별로 검색 결과를 필터링하거나 강조 표시할 수 있는 메타데이터 스키마를 동적으로 생성한다. 이러한 접근은 기존 XDB가 제공하던 “스키마 없는” 특성을 유지하면서도, 위키 페이지의 구조적 의미를 활용해 검색 정확도를 높인다.
프로토타입 구현은 Java 기반의 XDB 엔진 위에 Apache Lucene을 활용한 인덱싱 레이어를 추가함으로써 이루어졌다. 위키 페이지가 업데이트될 때마다 DARC 서버는 변경된 문서를 파싱하고, 해당 태그에 매핑된 필드에 텍스트를 삽입한다. 검색 요청이 들어오면 DARC는 Lucene 인덱스를 조회하고, 결과를 원본 위키 페이지 URL과 함께 반환한다. 이 과정에서 HTTP GET/POST 방식의 RESTful 인터페이스를 유지하므로, 기존 위키 클라이언트나 외부 애플리케이션이 별도의 라이브러리 없이도 손쉽게 통합할 수 있다.
성능 평가에서는 10,000개 위키 문서(평균 2KB)와 16개 태그 조합에 대해 평균 응답 시간이 120ms 이하로 측정되었으며, 태그 기반 필터링을 적용했을 때 검색 정확도가 기존 전체 텍스트 검색 대비 15% 향상된 것으로 보고되었다. 또한, 스키마 정의가 필요 없기 때문에 신규 태그를 추가하거나 다른 위키 방언으로 전환할 때 코드 수정이 최소화된다.
향후 과제는 현재 지원하는 16개 태그를 전면 확대하여 전체 MediaWiki 마크업을 포괄하고, Markdown, Creole 등 다른 위키 방언에 대한 파서 모듈을 추가하는 것이다. 또한, 분산 환경에서의 인덱스 동기화와 보안 인증 메커니즘을 강화해 대규모 기업 인트라넷에 적용 가능한 수준으로 성숙시킬 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기