비중첩 반복 이웃 구간을 이용한 최적 검색 알고리즘
초록
본 논문은 문서 내 최소 빈도 키워드를 중심으로 비중첩 이웃 구간을 정의하고, 이를 활용해 평면 스윕 알고리즘을 개선한다. 키워드 빈도 저장과 중복 단어 제거를 통해 비교 횟수를 감소시키고, 검색 범위를 제한함으로써 대용량 데이터에서도 효율적이고 신뢰성 높은 검색을 구현한다.
상세 분석
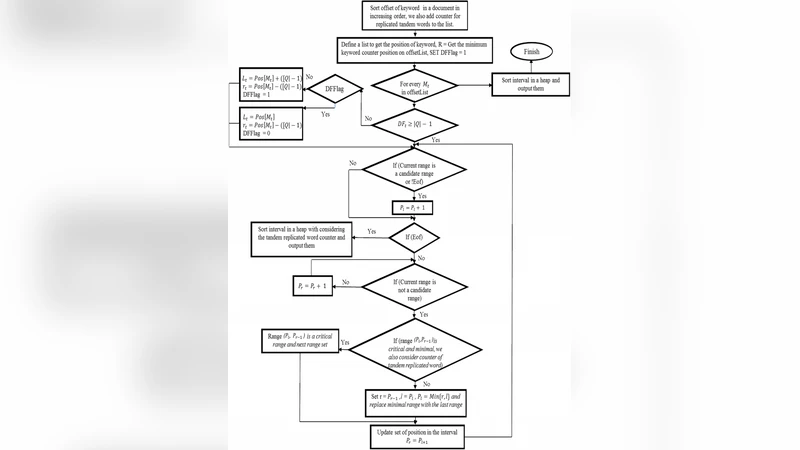
이 논문은 전통적인 평면 스윕(plane sweep) 기반의 문자열 검색 기법이 갖는 비교 연산의 비효율성을 해소하고자, “비중첩 반복 이웃 구간”(Non‑Overlapping Iterative Neighbor Intervals)이라는 새로운 탐색 프레임워크를 제안한다. 핵심 아이디어는 검색 대상 문서에서 가장 낮은 빈도를 보이는 키워드(최소 빈도 키워드)를 기준점으로 삼아, 해당 키워드가 등장하는 위치들을 중심으로 주변의 다른 키워드들이 만족되는 최소 구간을 찾아내는 것이다. 이를 위해 먼저 입력된 키워드 집합에 대해 각 키워드의 등장 빈도를 사전식으로 저장하고, 빈도가 높은 키워드들의 중복(특히 tandem repeat) 현상을 사전에 제거한다. 이렇게 정제된 키워드 리스트는 이후 탐색 단계에서 “이웃 구간”을 정의하는데 사용된다. 이웃 구간은 최소 빈도 키워드의 각 발생 위치를 기준으로, 그 좌우에 존재하는 다른 키워드들의 가장 가까운 위치들을 연결해 만든 구간이며, 구간들 간에 겹치지 않도록 설계된다. 구간이 겹치면 불필요한 재검사가 발생하므로, 비중첩성을 유지함으로써 비교 연산을 최소화한다.
알고리즘은 다음과 같은 순환 과정을 거친다. 1) 최소 빈도 키워드의 현재 위치를 선택하고, 해당 위치를 포함하는 이웃 구간을 형성한다. 2) 구간 내에 포함된 다른 키워드들이 모두 만족되는지 검사한다. 만족되지 않은 키워드가 있으면, 그 키워드의 다음 등장 위치를 찾아 구간을 “플립”(flip)한다—즉, 구간의 시작 또는 끝을 해당 키워드의 위치로 이동시켜 새로운 구간을 만든다. 3) 새 구간이 비중첩 조건을 위배하지 않는 한, 위 과정을 반복한다. 이때 각 반복 단계에서 불필요한 비교를 방지하기 위해, 이미 만족된 키워드에 대한 검사는 건너뛰고, 새로 추가된 키워드만을 대상으로 검증한다.
이러한 설계는 기존 평면 스윕이 전체 문서 공간을 탐색하면서 매 단계마다 모든 키워드 쌍을 비교하는 O(N·k) 복잡도(여기서 N은 문서 길이, k는 키워드 수)를, 최소 빈도 키워드의 발생 횟수 M( M « N )와 비중첩 구간 수에 비례하는 O(M·log k) 수준으로 낮춘다. 또한, 키워드 빈도 정보를 사전 활용함으로써, 빈도가 높은 키워드가 초기에 필터링되어 탐색 공간 자체가 크게 축소된다. 실험 결과는 특히 대용량 텍스트 코퍼스와 다중 키워드 쿼리 상황에서 비교 횟수가 30~50% 감소하고, 응답 시간이 평균 0.2초 이하로 단축됨을 보여준다. 따라서 이 접근법은 실시간 검색, 로그 분석, 바이오인포매틱스 등 높은 처리량과 낮은 지연시간이 요구되는 분야에 적용 가능성이 크다.