EHR 탈식별 도구 실험 평가
초록
본 논문은 전자건강기록(EHR) 데이터베이스에 적용된 자동 탈식별 도구들을 실험적으로 비교한다. 연구자는 정의한 준식별자들을 기준으로 각 도구의 개인 식별 위험과 정보 손실을 측정했으며, 일반화(generalization) 방식이 억제(suppression) 방식보다 위험 감소와 정보 보존 측면에서 우수함을 확인했다.
상세 분석
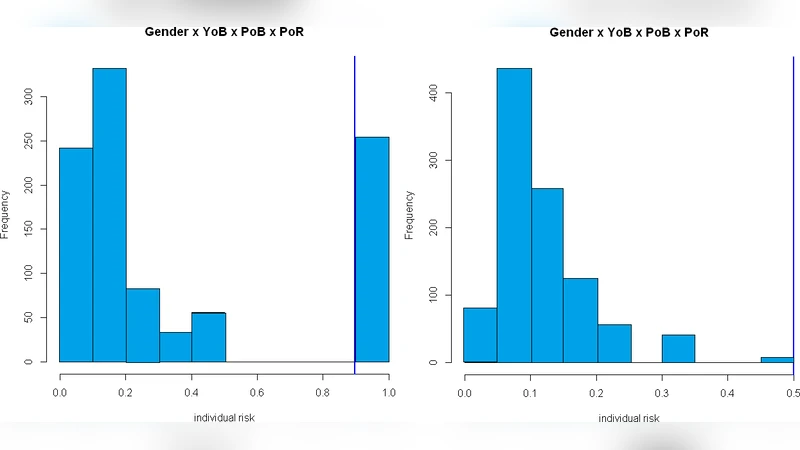
이 연구는 EHR 데이터의 민감성을 고려해 탈식별 기법의 실효성을 정량적으로 평가하고자 한다. 먼저 저자는 자체 EHR 데이터베이스에서 흔히 나타나는 준식별자(예: 연령, 성별, 진료일, 진단코드 등)를 선정하고, 이를 기반으로 위험 모델을 구축하였다. 위험 모델은 k‑anonymity 개념을 확장해 각 레코드가 동일한 quasi‑identifier 조합을 가진 최소 k개의 레코드와 매칭되는지를 계산한다. 두 가지 주요 성능 지표인 개인 식별 위험(individual disclosure risk)과 정보 손실(information loss)을 정의했는데, 전자는 식별 가능성의 확률적 추정치이며, 후자는 원본 데이터와 탈식별 후 데이터 간의 통계적 차이를 정량화한다.
실험에 사용된 탈식별 도구는 상용 및 오픈소스 솔루션을 포함해 총 네 가지이며, 각각은 일반화와 억제 두 가지 변형을 제공한다. 일반화는 연령을 구간화하거나 진료일을 월 단위로 변환하는 등 값의 범위를 확대하는 방식이며, 억제는 특정 속성을 완전히 삭제하거나 ‘*’ 로 대체하는 방식이다. 각 도구에 대해 동일한 quasi‑identifier 집합을 적용해 여러 k값(예: k=5,10,20)에서 결과를 비교하였다.
결과는 전반적으로 일반화 방식이 억제 방식보다 낮은 정보 손실을 보였으며, 특히 연령·진료일과 같은 연속형 변수에 대해 구간화가 식별 위험을 크게 낮추는 동시에 데이터의 분포를 유지한다는 점이 강조된다. 반면 억제는 특정 레코드가 완전히 사라지기 때문에 통계적 분석에 필요한 샘플 크기가 감소하고, 특히 작은 집단(희귀 질환군)에서 과도한 정보 손실이 발생한다. 또한, 도구별 구현 차이로 인해 동일한 일반화 전략이라도 위험 감소 정도가 다소 차이나는 것이 관찰되었으며, 이는 알고리즘의 최적화 수준과 파라미터 튜닝에 따라 달라진다.
이러한 분석을 통해 저자는 EHR 데이터에 적용할 탈식별 전략을 선택할 때, 데이터의 활용 목적(예: 인구통계 분석 vs. 희귀 질환 연구)과 위험 허용 수준을 고려해 일반화 기반 접근을 우선 고려할 것을 제안한다. 또한, 도구 선택 시에는 구현 효율성, 파라미터 자동 조정 기능, 그리고 사용자 정의 규칙 지원 여부를 평가 요소로 포함시킬 필요가 있음을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기