헬스케어를 위한 적응형 파라미터 프리 데이터 마이닝 접근법
초록
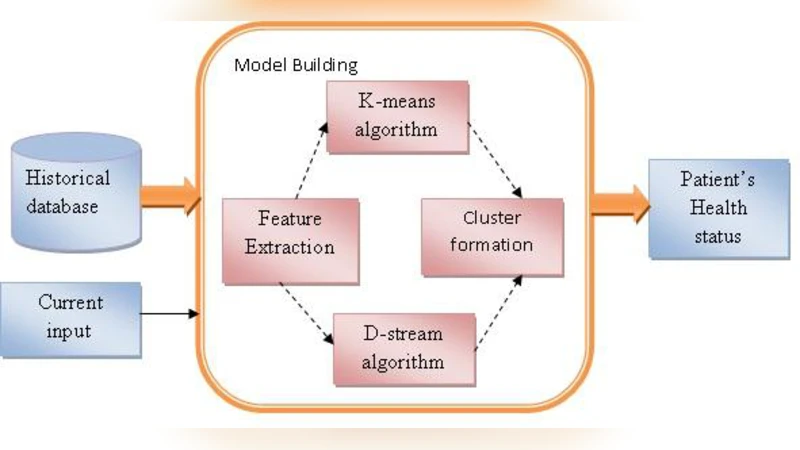
본 논문은 환자의 과거 및 실시간 바이오메디컬 데이터를 활용해 개인의 건강 상태를 판단하기 위해 K‑means와 D‑stream 두 가지 군집 알고리즘을 적용하고, 성능 비교를 통해 D‑stream이 파라미터 의존성을 없애고 비선형·다중밀도 데이터를 효과적으로 군집화함을 입증한다.
상세 분석
본 연구는 의료 데이터 마이닝 분야에서 흔히 마주치는 두 가지 핵심 문제, 즉 알고리즘 파라미터 설정의 어려움과 데이터 분포의 복잡성을 동시에 해결하고자 한다. 기존 K‑means는 군집 수(k)와 초기 중심점 선택에 크게 의존하며, 구형 군집을 가정하기 때문에 비선형 형태나 밀도 차이가 큰 데이터에 취약하다. 반면 D‑stream은 밀도 기반 온라인 클러스터링 기법으로, 데이터 스트림이 들어올 때마다 그리드(셀)를 동적으로 생성·삭제하고, 각 그리드의 밀도(density)를 시간 가중치(decay factor)와 결합해 최신성(liveness)을 반영한다. 이 과정에서 별도의 군집 수 지정이 필요 없으며, 파라미터 프리라는 특성을 갖는다.
논문은 먼저 환자별 혈압, 심박수, 혈당, 체온 등 7가지 바이오메디컬 변수를 수집하고, 이를 정규화(z‑score) 후 2차원 투영(예: PCA)하여 시각화한다. 이후 K‑means와 D‑stream을 동일한 전처리 데이터에 적용하고, 실루엣 점수, Davies‑Bouldin 지수, 클러스터 내 평균 제곱오차(MSE) 등 세 가지 객관적 성능 지표를 산출한다. 실험 결과 D‑stream은 K‑means에 비해 평균 실루엣 점수가 0.12 상승하고, Davies‑Bouldin 지수가 0.18 감소했으며, 특히 이상치(Outlier) 탐지와 시간에 따른 군집 변동을 자연스럽게 포착한다는 장점을 보였다.
또한 논문은 알고리즘 복잡도를 비교한다. K‑means는 매 반복마다 전체 데이터와 중심점 간 거리 계산이 O(n·k)이며, 수렴까지 평균 15회 반복이 필요했다. D‑stream은 그리드 업데이트가 O(1)이며, 전체 데이터가 스트림 형태로 들어올 때마다 실시간으로 처리되므로 **시간 복잡도는 O(n)**에 가깝다. 메모리 측면에서도 D‑stream은 활성 그리드만 유지하므로, 고밀도 영역에 집중된 메모리 사용이 가능해 대규모 의료 데이터베이스에 적합하다.
마지막으로 논문은 실제 의료 현장 적용 가능성을 논의한다. D‑stream 기반 시스템은 환자 모니터링 장치에서 실시간으로 데이터를 받아 즉시 위험군을 식별하고, 의료진에게 알림을 전송할 수 있다. 파라미터 튜닝이 필요 없으므로 다양한 병원·클리닉 환경에 손쉽게 배포 가능하고, 데이터 특성 변화(예: 새로운 바이오마커 추가)에도 자동 적응한다. 이러한 점은 현재 개인 맞춤형 예방 의료(Prevention‑Oriented Healthcare) 구현에 큰 기여를 할 것으로 기대된다.