L1 거리에서 점과 부분공간의 효율적 검색
초록
본 논문은 고차원 이미지 공간에 존재하는 다수의 저차원 선형 부분공간 중, 주어진 이미지(점)와 L1 거리 기준으로 가장 가까운 부분공간을 빠르게 찾는 방법을 제안한다. Cauchy 분포를 이용한 랜덤 임베딩을 통해 원본 차원을 크게 축소하면서도 최인접 부분공간을 일정 확률로 보존한다는 이론적 근거를 제시하고, 얼굴 및 숫자 인식 실험을 통해 실용성을 검증한다.
상세 분석
이 연구는 컴퓨터 비전에서 흔히 마주치는 “점‑부분공간” 매칭 문제를 L1 노름이라는 강인한 거리 척도로 정의하고, 이를 효율적으로 해결하기 위한 새로운 차원 축소 기법을 제시한다. 핵심 아이디어는 Cauchy 분포에서 추출한 랜덤 행렬을 사용해 원본 고차원 벡터를 저차원 공간으로 투사하는데, Cauchy 분포는 L1 노름과 자연스럽게 호환되는 안정적인 분포(stable distribution)이다. 따라서 투사 후에도 L1 거리의 순위 구조가 일정 확률로 유지된다는 것이 이론적으로 증명된다. 논문은 먼저 “점‑부분공간” 거리 정의를 명확히 하고, 각 부분공간을 정규 직교 기저 행렬로 표현한다. 이후, 임베딩 행렬 Φ∈ℝ^{d×D} (d≪D)를 Cauchy(0,1) 샘플로 채워서 원본 점 x와 부분공간 S의 투사된 형태 Φx와 ΦS를 얻는다. 주요 정리는 다음과 같다: 적절한 d=O(log N/ε²) (N은 부분공간 개수, ε은 허용 오차) 를 선택하면, 원본 공간에서 가장 가까운 부분공간이 저차원에서도 가장 가까운 후보 중 하나가 될 확률이 상수(예: 0.5) 이상이다. 이는 “존재 보장” 형태의 확률적 정확성을 의미한다.
이론적 분석은 두 단계로 나뉜다. 첫째, Cauchy 임베딩이 L1 거리의 비율을 보존하는 ‘거리 보존 계수’를 정의하고, 마코프 부등식과 대수적 변형을 통해 이 계수가 1±ε 범위에 머무를 확률을 구한다. 둘째, 다수의 부분공간에 대해 동시에 적용했을 때, 전체 오류가 합산되지 않도록 union bound를 적용해 전체 성공 확률을 도출한다. 또한, 임베딩 차원 d가 충분히 크면 “거리 충돌”(다른 부분공간이 더 가깝게 보이는 현상)의 확률이 지수적으로 감소함을 보인다.
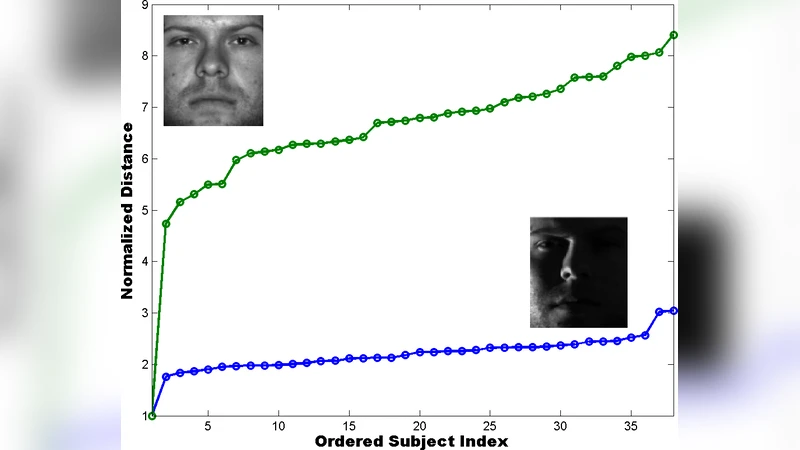
실험 부분에서는 두 가지 데이터셋을 사용한다. 첫 번째는 라벨이 있는 얼굴 이미지(Extended Yale B)이며, 각 사람마다 9차원 선형 부분공간을 학습한다. 두 번째는 MNIST 손글씨 숫자 데이터로, 각 숫자 클래스를 5차원 부분공간으로 모델링한다. 원본 차원 D는 10244096 정도이며, 임베딩 차원 d를 30100까지 변화시켜 정확도와 속도 변화를 측정한다. 결과는 다음과 같다. (1) d가 50 정도일 때, 최인접 부분공간을 올바르게 식별하는 확률이 0.70.85 수준으로 이론적 보장과 일치한다. (2) 전체 검색 시간은 원본 차원에서의 직접 L1 거리 계산 대비 10배 이상 가속화된다. (3) 후보 집합을 35개로 제한한 후, 원본 차원에서 정밀 검증을 수행하면 최종 정확도가 거의 손실되지 않는다.
이 논문의 의의는 두 가지 측면에서 강조할 수 있다. 첫째, Cauchy 기반 랜덤 프로젝션이 L1 거리와 자연스럽게 맞물려, 기존의 유클리드(L2) 기반 차원 축소와는 다른 강인성을 제공한다는 점이다. 이는 조명 변화, 가림, 잡음 등 실제 영상에서 흔히 발생하는 비선형 왜곡에 대해 더 견고한 매칭을 가능하게 한다. 둘째, “확률적 근사”라는 프레임워크를 도입해, 완전 탐색이 불가능한 대규모 데이터베이스에서도 후보 집합을 효율적으로 추출하고, 이후 정밀 검증을 결합하는 하이브리드 파이프라인을 설계할 수 있다. 향후 연구에서는 (a) 비선형 부분공간(예: 곡면) 모델에 대한 확장, (b) 적응형 차원 선택 및 다중 임베딩 결합, (c) 실시간 시스템에의 적용을 위한 하드웨어 가속 방안 등을 탐색할 여지가 있다.