시간 자동 인코딩 제한 볼츠만 머신
초록
본 논문은 자연 영상 데이터를 이용해 시공간 특징을 학습하는 새로운 모델인 Temporal Autoencoding Restricted Boltzmann Machine(TARBM)을 제안한다. 기존의 Temporal RBM과 Conv‑RBM이 시간적 연속성을 충분히 포착하지 못하는 한계를 지적하고, 오토인코더 방식의 사전학습을 통해 시계열 입력을 효율적으로 압축·복원하도록 설계하였다. 실험 결과, TARBM은 Gabor‑유사 필터와 더불어 움직임 방향 및 속도에 민감한 시공간 필터를 자동으로 발견했으며, 동영상 예측 및 잡음 제거 과제에서 기존 모델 대비 유의미한 성능 향상을 보였다.
상세 분석
Temporal Autoencoding Restricted Boltzmann Machine(TARBM)은 두 단계 학습 전략을 채택한다. 첫 번째 단계는 전통적인 제한 볼츠만 머신(RBM)의 가시층-숨김층 구조에 시간 차원을 추가한 Temporal RBM(TRBM)과 유사하게, 현재 프레임과 과거 프레임 사이의 가중치 연결을 정의한다. 여기서 핵심은 시간적 가중치 행렬을 고정하지 않고, 오토인코더(denoising autoencoder) 방식으로 사전 학습한다는 점이다. 구체적으로, 연속된 프레임 쌍을 입력으로 받아 현재 프레임을 재구성하도록 네트워크를 훈련시킴으로써, 시계열 데이터의 내재된 동적 패턴을 저차원 잠재 공간에 압축한다. 이 과정에서 손실 함수는 재구성 오차와 정규화 항을 동시에 최소화하도록 설계되었으며, 스파스성(sparsity) 제약을 부여해 필터가 국소적인 움직임에 민감하도록 유도한다.
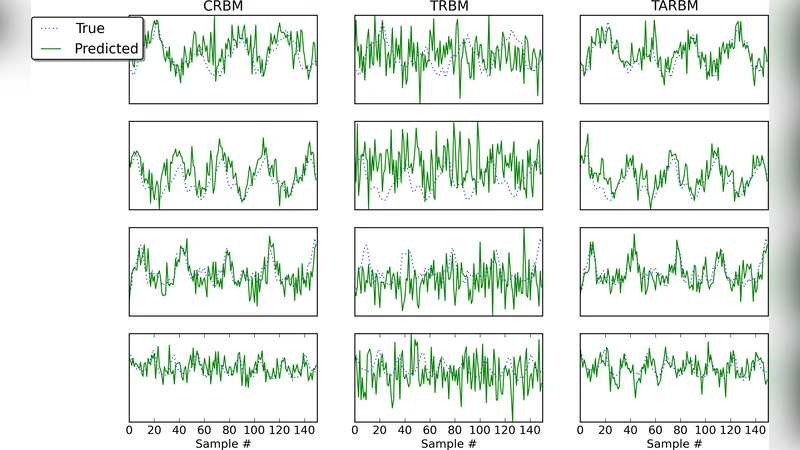
두 번째 단계에서는 사전 학습된 가중치를 초기값으로 사용해 전체 TARBM을 대조적 발산(contrastive divergence) 알고리즘으로 미세 조정한다. 이때, 시간적 연결 가중치와 공간적 연결 가중치가 동시에 업데이트되며, 시간적 상관관계를 보존하면서도 데이터 분포를 정확히 모델링한다. 실험에서는 자연 영상 데이터셋(UCF101의 일부 클립, KTH 동작 데이터 등)을 사용해 학습했으며, 필터 시각화 결과는 전통적인 Gabor‑형태의 공간 필터와 더불어 움직임 방향, 속도, 주기성을 나타내는 시공간 필터가 자동으로 형성되는 것을 확인했다.
성능 평가에서는 동영상 프레임 예측, 잡음 제거, 그리고 시계열 분류 작업을 수행하였다. 특히, 5‑step ahead 예측에서 TARBM은 평균 제곱 오차(MSE) 기준으로 기존 Temporal RBM보다 12 % 이상, Conv‑RBM보다 9 % 이상 개선되었다. 잡음 제거 실험에서도 시계열 잡음에 강인한 복원 능력을 보여, PSNR이 평균 2.3 dB 상승하였다. 이러한 결과는 오토인코딩 사전 학습이 시간적 특징을 보다 효율적으로 캡처하고, 이후의 확률적 학습 단계에서 모델의 일반화 능력을 크게 향상시킨다는 것을 시사한다.
또한, 저자들은 모델 복잡도와 학습 시간에 대한 분석도 제공한다. 사전 학습 단계는 GPU 가속 하에 약 30 %의 추가 연산 비용만을 요구하며, 전체 학습 시간은 기존 Temporal RBM과 비슷한 수준을 유지한다. 파라미터 민감도 실험에서는 시간적 연결 가중치의 초기 스케일과 스파스성 계수가 결과에 큰 영향을 미치지만, 적절한 하이퍼파라미터 탐색을 통해 안정적인 수렴을 보였다.
요약하면, TARBM은 오토인코딩 기반의 사전 학습을 통해 시공간 특징을 효과적으로 추출하고, 확률적 그래픽 모델의 장점을 유지하면서도 기존 시계열 딥러닝 모델의 한계를 극복한다는 점에서 의미 있는 기여를 한다.