조건부 추론을 위한 영가 분포 추정과 유전체 규모 스크리닝
초록
본 논문은 Efron이 제안한 영가 분포 추정 방법을 조건부 추론의 관점에서 재조명하고, 이를 이용한 새로운 다중 비교 절차를 제시한다. 시뮬레이션과 마이크로어레이 데이터 분석을 통해 추정된 영가 분포가 조건부 신뢰 수준을 개선하고, 정보이론적 점수로 추정 영가 분포의 활용 가치를 평가한다.
상세 분석
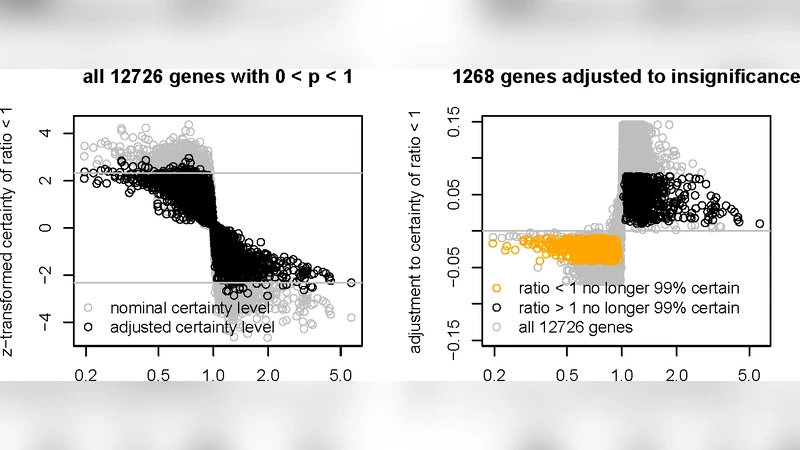
이 연구는 대규모 유전체 데이터에서 수천 개에 달하는 가설 검정을 수행할 때, 전통적인 영가 가정(표준 정규분포) 대신 데이터에 내재된 실제 영가 분포를 추정함으로써 통계적 효율성을 높이는 방법을 제시한다. Efron(2004, 2007)의 접근법을 기반으로, p‑값을 정규 분위수로 변환한 뒤 중앙 영역을 중심으로 정규분포의 평균과 분산을 최대우도 추정(MLE)하거나 커브 피팅을 통해 추정한다. 이러한 추정은 “대부분(≈90 %)의 p‑값이 실제 영가 가설에 해당한다”는 가정에 의존하며, 극단적인 p‑값은 대안 가설에서 온 것으로 간주한다.
논문은 먼저 신뢰 수준을 사후 확률로 해석하는 통계적 프레임워크를 구축한다. 여기서 관측 데이터 x는 파라미터 ξ에 대한 확률분포 Pξ를 정의하고, 관심 파라미터 θ와 잡음 파라미터 γ를 구분한다. 정의된 신뢰 구간 ˆΘρ,s(ρ)는 커버리지 ρ를 만족하도록 설계되며, 이는 전통적인 p‑값과는 별개의 “관측 신뢰 수준”으로 해석된다. 이 신뢰 수준은 베이지안 사후 확률과 동일한 형태를 가지지만, 베이즈 정리의 업데이트 규칙을 강제하지 않는다. 따라서 손실 함수 최소화에 기반한 의사결정 규칙과 일관성을 유지하면서도 단일 표본에 대한 조건부 정보를 최대한 활용한다.
핵심적인 기여는 추정된 영가 분포를 “근사 부수통계량(approximate ancillary statistic)”으로 간주하고, 이를 조건부로 신뢰 수준을 재계산함으로써 조건부 추론을 개선한다는 점이다. 시뮬레이션에서는 실제 영가 분포가 표준 정규와 차이가 있을 때, 추정된 영가 분포에 조건부로 신뢰 수준을 조정하면 평균 커버리지 오차가 크게 감소한다. 또한, 정보이론적 점수—즉, 부수통계량의 부수성(degree of ancillarity)과 추론 관련성(degree of inferential relevance)의 합—를 도입해 특정 데이터셋에 대해 영가 분포 추정이 유용한지를 정량화한다. 이 점수는 부수성이 높을수록(즉, 추정된 영가 분포가 데이터에 거의 영향을 받지 않을수록) 조건부 추론의 이득이 커짐을 의미한다.
실제 마이크로어레이 데이터에 적용한 결과, 기존의 표준 영가 가정에 기반한 FDR 제어보다 추정된 영가 분포를 이용한 방법이 더 적은 거짓 양성률과 더 높은 검출력을 제공한다. 특히, 스크리닝 목적(다수의 후보를 빠르게 선별)에서 비가산 손실 함수(non‑additive loss function)를 사용하면, 전체 손실을 최소화하는 임계값이 기존 방법보다 완화되어 더 많은 실제 양성을 포착한다.
이 논문은 영가 분포 추정이 단순히 p‑값 보정에 그치지 않고, 조건부 신뢰 수준을 재정의함으로써 다중 비교 문제 전반에 걸친 통계적 효율성을 향상시킬 수 있음을 보여준다. 또한, 부수통계량의 부수성과 추론 관련성을 동시에 고려한 정보이론적 평가 기준을 제시함으로써, 연구자가 특정 데이터에 대해 영가 추정이 실제로 도움이 되는지를 사전에 판단할 수 있는 실용적인 도구를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기