질문을 답으로 생명과학 데이터 지식 기반 질의 시스템의 효용
초록
본 논문은 전통적인 관계형 데이터베이스와 폼 기반 인터페이스를 이용한 질의 방식과, 대규모 OWL 온톨로지를 기반으로 RDF 인스턴스를 활용하는 지식‑구동형 질의 시스템을 비교한다. 동일한 세포생물학 데이터셋을 두 시스템에 적용하고, 실제 연구팀이 일상 업무에서 병행 사용한 결과를 정성적으로 평가한다. 지식‑구동형 접근이 질의 표현의 유연성, 재사용성, 통합성 측면에서 장점을 보이며, 동시에 온톨로지 구축·보수 비용과 사용자 학습 곡선이라는 한계를 지닌다.
상세 분석
이 연구는 두 가지 질의 접근법을 실제 생명과학 현장에서 동시에 운영함으로써, 이론적 장점이 실무에 어떻게 구현되는지를 실증적으로 탐색한다. 전통적 방식은 관계형 데이터베이스에 데이터를 정규화하고, 연구자들이 자주 사용하는 “프리‑캔” 질의를 폼 형태로 제공한다. 이러한 인터페이스는 사용성이 뛰어나고, 비전문가도 클릭 몇 번으로 원하는 결과를 얻을 수 있다는 장점이 있다. 그러나 질의가 사전에 정의된 템플릿에 묶여 있어, 새로운 연구 질문이 등장하면 시스템을 재구성하거나 새로운 폼을 개발해야 하는 비효율성이 존재한다.
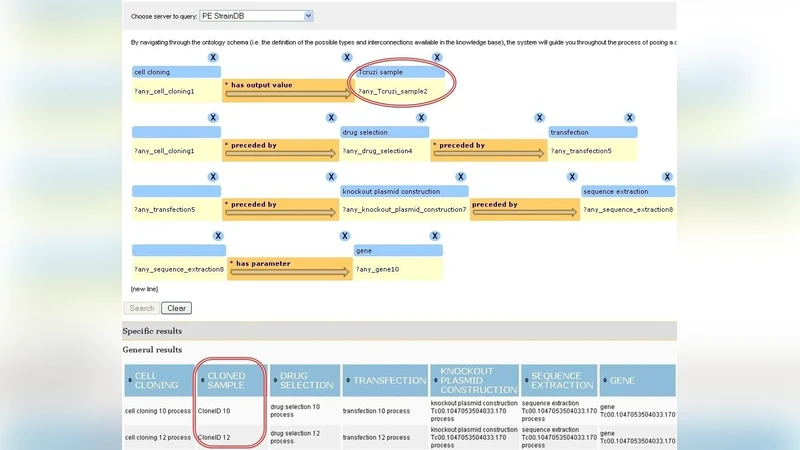
반면, 지식‑구동형 시스템은 광범위한 OWL 온톨로지를 구축하고, 기존 데이터셋을 RDF 트리플 형태로 매핑한다. 사용자는 트리플 기반 질의 편집기를 통해 개념, 속성, 관계를 자유롭게 조합해 질의를 작성한다. 이 접근법은 (1) 의미적 일관성을 보장하면서 다양한 도메인 간 데이터 통합이 가능하고, (2) 질의 재사용 및 자동 완성 기능을 통해 연구자가 복잡한 질문을 빠르게 구체화할 수 있다는 점에서 큰 강점을 가진다. 특히, 온톨로지에 정의된 계층 구조와 논리 규칙을 활용하면, 암묵적인 생물학적 지식을 질의에 내재화할 수 있어, 기존 데이터베이스에서는 어려운 “추론 기반” 답변을 도출할 수 있다.
하지만 온톨로지 구축은 전문 인력이 필요하고, 초기 모델링 비용이 높다. 또한, RDF 트리플 저장소는 대규모 데이터에 대해 성능 최적화가 필요하며, 질의 작성 시 SPARQL 같은 전문 언어에 대한 학습이 요구된다. 연구팀은 이러한 한계를 완화하기 위해 직관적인 트리플 편집 UI와 자동 완성 기능을 제공했지만, 여전히 일부 사용자는 복잡한 질의 구조에 진입 장벽을 느꼈다.
정성적 평가에서는, 연구자들이 전통적 폼 기반 질의에 비해 지식‑구동형 시스템을 사용할 때 초기 학습 시간이 길었지만, 장기적으로는 새로운 가설을 탐색하고 다중 데이터 소스를 결합하는 작업에서 효율성이 크게 향상된 것으로 나타났다. 또한, 온톨로지 기반 질의는 결과 해석 시 의미적 메타데이터를 함께 제공함으로써, 데이터의 출처와 신뢰성을 검증하는 데 도움이 되었다.
결론적으로, 본 논문은 지식‑구동형 질의 시스템이 복잡하고 변화가 잦은 생명과학 연구 환경에서 유연성과 확장성을 제공한다는 점을 실증적으로 입증한다. 동시에, 온톨로지 유지·보수와 사용자 교육이라는 비용을 고려한 혼합 전략이 현실적인 전환 경로가 될 수 있음을 시사한다.