상관성을 활용한 차등 발현 유전자 탐지 혁신: Tellipsoid
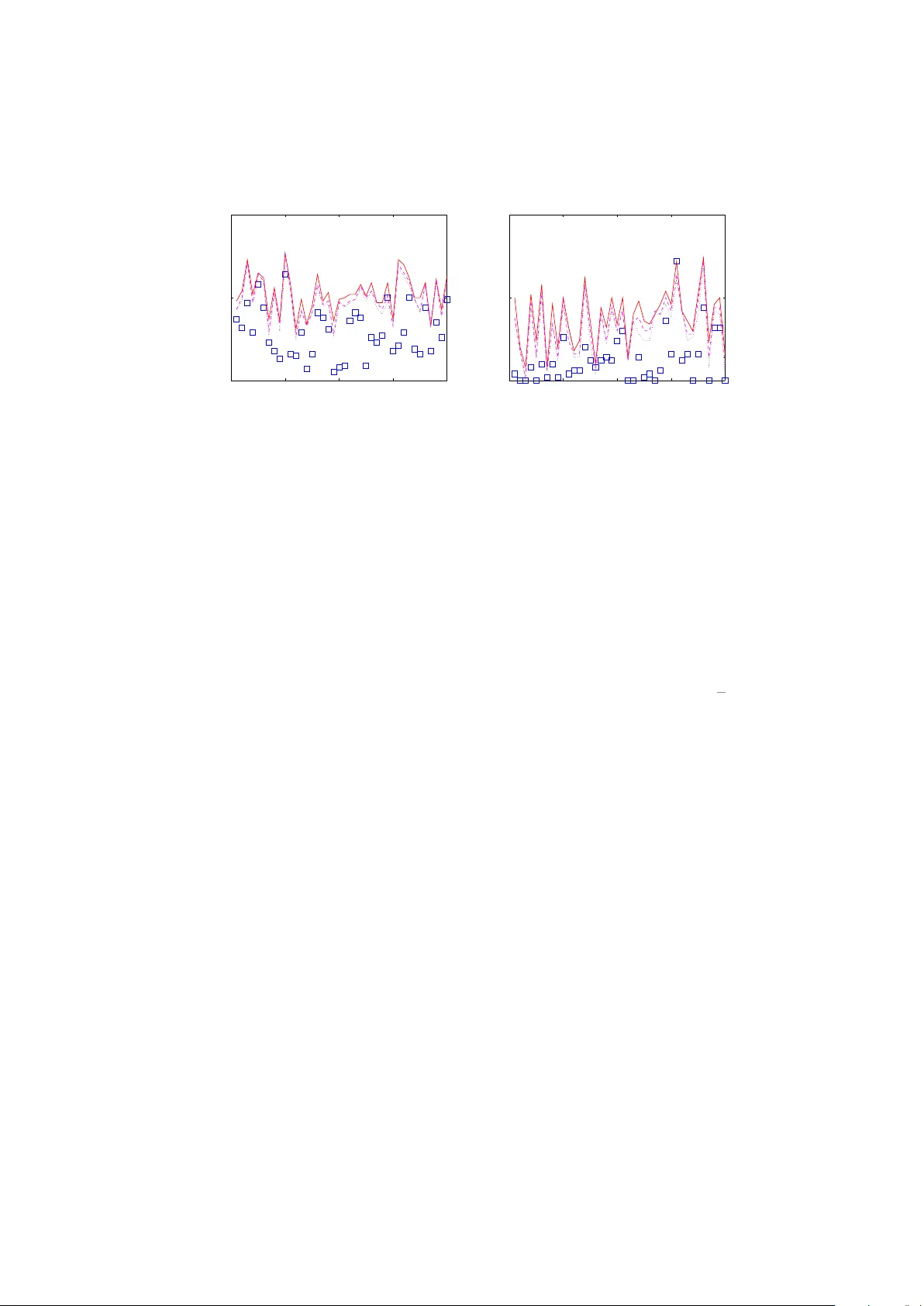
Tellipsoid은 마할라노비스 거리를 최적화 기준으로 사용해 유전자 간 상관성을 공유함으로써 기존 t‑검정 기반 차등 발현 분석의 통계적 검출력을 크게 향상시킨다. 논문은 “Zero Assumption”(가장 작은 t값을 갖는 일정 비율의 유전자는 무차별(null)이라고 가정)과 표본 상관 행렬을 이용해 t‑통계량의 평균 벡터를 추정하고, 이를 기반으로 새로운 순위 지표 û를 계산한다. 실험 결과는 전립선 암 데이터에서 SAM·EDGE 등…
저자: Keyur Desai, J.R. Deller, Jr.
**1. 서론**
마이크로어레이 실험에서 차등 발현 유전자를 탐지하는 것은 생물학적 인사이트를 얻는 핵심 단계이다. 기존 방법들은 주로 두 집단 간 평균 차이를 t‑통계량으로 요약하고, 이를 절대값 순으로 랭킹한다. 그러나 유전자 간 상관성이 존재하면 FDR 추정이 불안정해지고, 검출력이 저하될 수 있다. 저자들은 이러한 상관성을 ‘제어’하는 것이 아니라 ‘활용’하여 검정력을 높일 수 있다고 주장한다. 핵심 아이디어는 (1) 대부분의 유전자는 사전에 비차별(null)이라고 판단할 수 있는 ‘identifiability’를 가정하고, (2) 다변량 정규 모델에서 Mahalanobis 거리를 최소화하는 새로운 평균 추정량 û를 도입하는 것이다.
**2. 방법론**
- **2.1 t‑통계량 정의**: 각 유전자 i에 대해 전통적인 두 표본 t‑통계량 t_i = ( \bar{x}_{i,2} − \bar{x}_{i,1} )/s_i 를 계산한다.
- **2.2 Zero Assumption (ZA)**: |t| 순으로 정렬하고, 하위 P % (기본값 50 %)를 무조건 null이라고 가정한다. 이를 통해 t‑벡터를 t^(0) (null 부분)와 t^(1) (잠재적 non‑null 부분)으로 분할한다.
- **2.3 다변량 정규 가정**: t ∼ N(u, Σ) 로 가정하고, Mahalanobis 거리 d(t,u)=√{(t−u)ᵀΣ⁻¹(t−u)} 를 최소화한다. ZA에 의해 u의 앞 c개 원소는 0으로 고정된다.
- **2.4 û의 닫힌 형태**: 최소화 문제를 풀면 û^(1)=t^(1)−Σ₁₀ Σ₀₀⁻¹ t^(0) 가 얻어진다. 여기서 Σ₁₀, Σ₀₀는 각각 null‑non‑null, null‑null 공분산 행렬이다.
- **2.5 공분산 추정**: 직접 Σ를 추정하기보다, 원본 발현 행렬 X에서 각 그룹 평균을 제거한 eX를 만든 뒤, 표본 상관 행렬 Ĉ를 계산한다. Ĉ는 Σ와 비례하므로 Σ₀₀⁻¹ t^(0) 를 Ĉ₀₀⁻¹ t^(0) 로 대체한다.
- **2.6 최종 순위**: û_i 의 절대값 |û_i| 를 기준으로 유전자를 랭킹한다.
**3. 알고리즘 구현**
1. 두 그룹에 대한 t‑통계량 계산.
2. |t| 순으로 정렬 후 ZA에 따라 c를 결정 (기본 P=50 %).
3. X를 그룹 평균을 빼서 eX로 변환.
4. eX의 표본 상관 행렬 Ĉ 계산 (대각에 10⁻¹⁰ 추가해 비특이성 방지).
5. 선형 시스템 Ĉ₀₀ x = t^(0) 를 Cholesky 분해 등 효율적인 방법으로 풀어 x 구함.
6. û^(1)=t^(1)−Ĉ₁₀ x 계산 후 û =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기