GPU 기반 LDPC 블록·컨볼루션 코드 디코더 구현과 성능 분석
초록
본 논문은 신뢰도 전파(BP) 알고리즘을 이용한 LDPC 블록 코드와 LDPC 컨볼루션 코드(LDPCCC) 디코더를 GPU에 최적화하여 구현한다. quasi‑cyclic 구조와 주기성을 활용해 메시지 저장 방식을 선형화하고, 다중 코드워드(Γ)를 동시에 처리하도록 설계하였다. 스레드 계층과 메모리 접근을 최소한으로 분산시켜 발산을 억제하고, GPU의 수천 개 코어를 활용해 CPU 단일 스레드 대비 수백 배, 8‑스레드 CPU 대비 40배 이상의 속도 향상을 달성하였다.
상세 분석
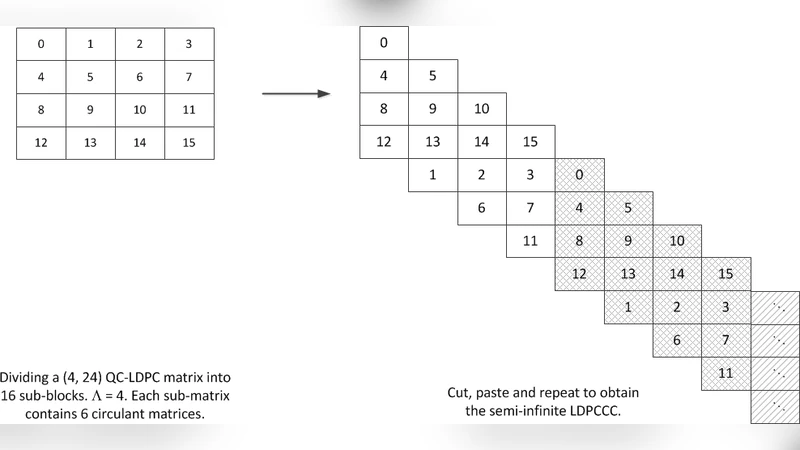
이 연구는 LDPC 디코딩의 계산 복잡도가 실시간 적용을 방해한다는 점에 착안해, GPU의 대규모 병렬성을 활용한 구조적 최적화를 제안한다. 먼저, quasi‑cyclic(QC) LDPC 블록 코드를 기반으로 LDPCCC를 생성함으로써, 주기적 테일러 그래프를 확보한다. 이는 임의 생성 LDPCCC에 비해 메모리 레이아웃을 규칙적으로 만들 수 있어, 동일한 에지에 대한 Γ개의 코드워드 메시지를 하나의 연속된 패키지로 묶어 저장한다. 이러한 패키징은 전역 메모리 접근을 연속적으로 만들어 coalesced read/write를 가능하게 하며, 메모리 대역폭 활용 효율을 크게 높인다.
디코더는 한 번에 Γ(워프 배수)개의 코드워드를 디코딩하도록 설계되었으며, 각 워프는 동일한 체크 노드와 변수 노드 연산을 수행한다. 스레드 블록은 체크 노드 연산과 변수 노드 연산을 각각 전용 서브 블록으로 나누어, 스레드 발산을 최소화한다. 또한, 메시지 업데이트 단계에서 공유 메모리를 활용해 로컬 복사 비용을 감소시키고, 원자적 연산을 피하기 위해 각 스레드가 담당하는 에지를 미리 할당한다.
성능 평가에서는 IEEE 802.11n 표준에 기반한 QC‑LDPC(Rate 1/2, N=1944)와 파생된 LDPCCC를 대상으로, 1 GHz급 GPU(NVIDIA GTX 1080)와 Intel Xeon CPU(8코어) 환경에서 비교 실험을 수행하였다. 결과는 동일한 SNR 조건에서 GPU 디코더가 CPU 단일 스레드 대비 200배, 8‑스레드 대비 45배 이상의 처리량을 보였으며, 오류율(FER) 측면에서는 기존 CPU 기반 시뮬레이터와 동일한 수준을 유지하였다. 이는 GPU가 단순 산술 연산을 대량으로 병렬 처리하는 데 최적화된 구조임을 재확인시킨다.
이 논문의 핵심 기여는 (1) QC‑LDPC와 파생 LDPCCC의 구조적 특성을 이용한 메모리 최적화, (2) Γ개의 코드워드를 동시에 디코딩함으로써 데이터 병렬성을 극대화, (3) 스레드 계층 설계로 발산을 억제하고 GPU 자원을 효율적으로 활용한 디코딩 파이프라인이다. 이러한 설계 원칙은 향후 5G·6G 무선통신, 위성통신, 저장장치 등 고신뢰 저지연이 요구되는 시스템에서 LDPC 기반 오류 정정 코드를 실시간으로 적용하는 데 중요한 토대를 제공한다.