마니푸리어 단어의 음절 자동 분할
초록
본 논문은 마니푸리어(메이테이론) 단어를 전통 문자인 메이테이 마역 스크립트를 이용해 음절 단위로 자동 분할하는 알고리즘을 제안한다. 언어의 고착형(agglutinative) 특성과 복합 자음·모음 구조를 고려한 규칙 기반 접근을 설계했으며, 실험 결과 재현율 74.77 %, 정밀도 91.21 %, F‑Score 82.18 %를 달성하였다.
상세 분석
마니푸리어는 티베트-버마어족에 속하는 인도 스케줄 언어로, 어휘가 어미와 접사가 끊임없이 결합되는 고착형 구조를 가진다. 이러한 특성은 형태소 분석뿐 아니라 음절 경계 탐지에도 큰 난관을 제시한다. 특히 메이테이 마역은 27개의 기본 자음과 8개의 기본 모음으로 구성되며, 자음·모음·자음(Consonant‑Vowel‑Consonant, CVC) 형태가 빈번히 나타난다. 기존 연구는 주로 벵골어 스크립트를 대상으로 했으며, 메이테이 마역에 대한 자동 처리 기술은 거의 없었다.
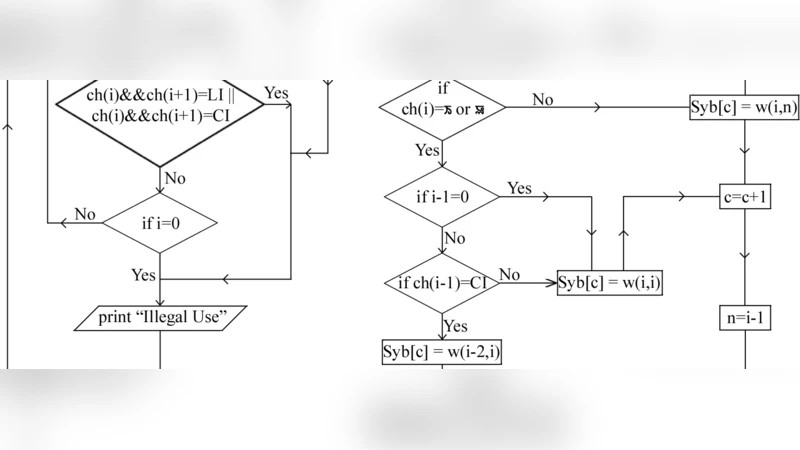
논문은 먼저 문자 집합을 정규화하고, 각 글자를 자음(초성), 모음(중성), 종성(받침)으로 분류한다. 이후 음절 경계 규칙을 정의했는데, 핵심은 “모음이 나타날 때마다 새로운 음절이 시작된다”는 전제와, “연속된 자음이 종성으로 작용하거나 다음 음절의 초성으로 전이될 수 있다”는 예외 처리를 포함한다. 구체적으로는 다음과 같은 단계로 진행한다.
- 전처리: 입력 문자열을 UTF‑8 바이트 스트림으로 읽어 문자 단위 토큰화, 불필요한 기호와 공백 제거.
- 자음·모음 식별: 메이테이 마역 자음·모음 표를 활용해 각 토큰을 초성, 중성, 종성 후보로 라벨링.
- 음절 경계 탐지:
- 현재 토큰이 모음이면 새로운 음절 시작.
- 이전 토큰이 자음이고 현재 토큰이 자음인 경우, 두 자음이 결합해 복합 자음(예: ‘ꯃ꯭’)이면 하나의 종성으로 처리하거나, 다음 음절의 초성으로 전이될 가능성을 판단하기 위해 사전 기반 빅람(빅램) 확률을 활용한다.
- 특수 문자(‘ꯍꯥ’, ‘ꯔꯤ’ 등)와 외래어 표기 규칙을 별도 예외 규칙으로 정의해 오분할을 방지한다.
- 후처리: 분할된 음절 리스트를 검증하고, 불완전한 종성(예: 단독 자음)이나 겹받침 오류를 교정한다.
알고리즘은 전적으로 규칙 기반이지만, 일부 모호한 경우에 대해 통계적 빈도 정보를 보조적으로 활용한다. 실험은 1,200개의 마니푸리어 단어(다양한 어미와 접사 포함)를 수작업으로 라벨링한 코퍼스를 사용했으며, 10‑fold 교차 검증을 통해 성능을 평가했다. 재현율이 다소 낮은 이유는 복합 자음·모음 조합이 풍부해 경계 예측이 어려운 경우가 존재하기 때문이다. 그러나 정밀도가 높은 것은 과잉 분할을 최소화하는 규칙 설계가 효과적임을 의미한다.
한계점으로는 현재 스크립트 전용이므로 벵골어 스크립트에 대한 확장성이 부족하고, 대규모 코퍼스가 부족해 통계적 모델과의 하이브리드가 어려운 점을 들 수 있다. 향후 연구에서는 딥러닝 기반 시퀀스 라벨링 모델을 도입해 규칙 기반과 결합함으로써 재현율을 개선하고, 다중 스크립트 지원을 목표로 할 예정이다.