이기종 하둡 클러스터 성능 최적화 방안
초록
본 논문은 클라우드 환경에서 이기종(heterogeneous) 하둡 클러스터가 겪는 성능 저하 원인을 분석하고, 노드 자원 차이를 고려한 작업 스케줄링, 데이터 로컬리티 향상, 사양 기반 복제 전략 등 실용적인 개선 방안을 제시한다.
상세 분석
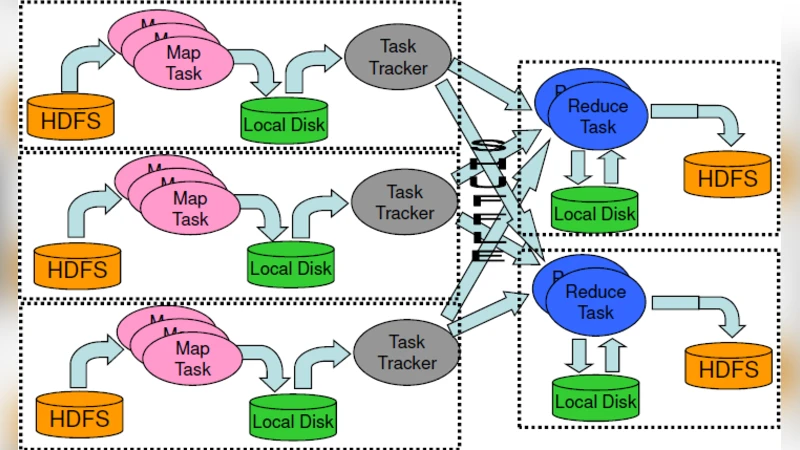
하둡은 기본적으로 동일한 CPU, 메모리, 디스크 사양을 가진 노드가 모여야 최적의 성능을 발휘하도록 설계되었다. 그러나 실제 클라우드 서비스에서는 비용 절감을 위해 서로 다른 사양의 가상 머신을 혼합해 클러스터를 구성하는 경우가 빈번하다. 이러한 이기종 환경에서는 몇 가지 핵심 문제가 발생한다. 첫째, 작업 스케줄러가 노드의 처리 능력을 무시하고 동일한 크기의 블록을 할당하면, 저사양 노드에서 작업이 오래 걸리면서 전체 작업 완료 시간이 늘어난다(스트래깅 현상). 둘째, 데이터 로컬리티가 저하된다. 고성능 노드에 데이터가 집중되면 네트워크를 통한 데이터 전송이 빈번해져 I/O 병목이 발생한다. 셋째, 복제와 장애 복구 메커니즘이 사양을 고려하지 않으면, 복제본이 저사양 노드에 저장돼 재복구 시 속도가 급격히 떨어진다. 넷째, 기존의 speculative execution(추정 실행) 기능이 무작위로 복제 작업을 실행해 오히려 리소스 낭비를 초래한다. 이러한 문제들을 해결하기 위해서는 노드별 CPU, 메모리, 디스크 I/O, 네트워크 대역폭을 정량화해 가중치를 부여하고, 가중치 기반 스케줄링을 적용해야 한다. 또한, 데이터 블록을 사전 분석해 노드 사양에 맞는 블록 크기와 복제 수를 동적으로 조정하고, YARN의 Capacity Scheduler나 Fair Scheduler를 활용해 자원 풀을 계층화한다. speculative execution은 성능이 현저히 낮은 노드에만 제한적으로 적용하고, 네트워크 대역폭이 충분한 경우에만 활성화한다. 마지막으로, 모니터링 툴을 통해 실시간으로 노드 성능 변동을 감지하고, 자동으로 작업 재배치를 수행하는 피드백 루프를 구축하면 이기종 클러스터에서도 안정적인 처리량을 유지할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기