관계형 데이터 마이닝을 위한 대표 예시 추출 방법
초록
본 논문은 관계형 데이터셋에서 대표성을 정량화하는 “대표도” 개념을 제안하고, 이를 Borda 집계 절차와 결합해 데이터의 대표 예시(Exemplar)를 자동으로 추출한다. 추출된 예시는 네트워크 구조를 형성하는 핵심 노드로 활용될 수 있으며, 이론적 성질과 두 가지 실용 사례(이진 이미지 요약·연구팀 공동 저자 관계 분석)를 통해 프레임워크의 유용성을 입증한다.
상세 분석
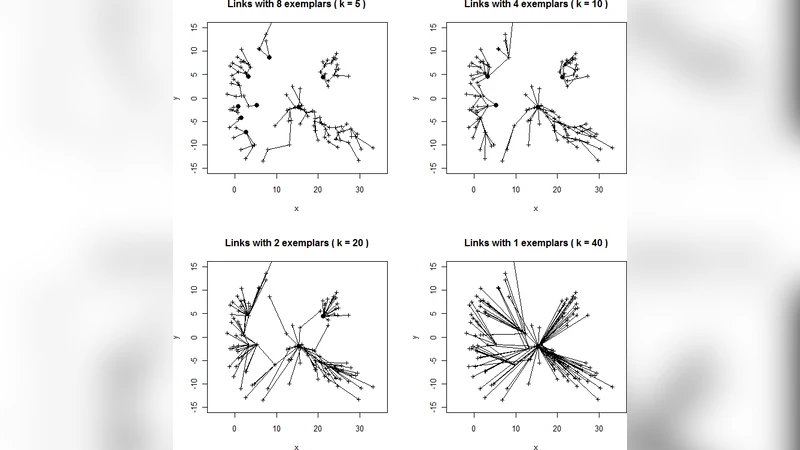
논문은 먼저 관계형 데이터 마이닝에서 “대표성(degree of representativeness)”을 정의한다. 각 객체 i는 다른 객체 j에 대해 유사도 혹은 거리 함수를 통해 순위를 매기고, 이 순위들을 Borda 점수로 변환한다. Borda 점수는 모든 비교 대상에 대한 순위의 합으로 계산되며, 높은 점수를 받은 객체는 전체 데이터셋에 대해 상대적으로 더 많이 선호된다는 의미이다. 이렇게 얻어진 점수를 정규화하여 각 객체의 대표도를 구하고, 특정 임계값 혹은 상위 k개의 객체를 “예시(exemplar)”로 선정한다.
대표 예시 추출 과정은 두 단계로 나뉜다. 첫 번째는 모든 객체 간의 쌍대 순위 매트릭스를 구축하는데, 이는 비대칭적일 수 있다(예: 거리 비대칭). 두 번째는 Borda 집계를 통해 각 객체의 누적 점수를 계산하고, 이를 기반으로 대표도를 산출한다. 대표도는 0과 1 사이의 값으로 정규화되며, 데이터 밀도, 군집 구조, 그리고 노이즈 수준에 민감하게 반응한다.
논문은 이론적 성질을 네 가지 정리로 제시한다. (1) 대표도는 전체 데이터셋에 대해 순위 일관성을 유지한다. (2) 대표 예시 집합은 데이터셋을 완전 커버하는 최소 지배 집합(dominating set)과 동등함을 보인다. (3) Borda 기반 대표도는 거리 함수가 메트릭일 경우 삼각 부등식을 만족한다. (4) 대표 예시 선택은 파라미터(예: 임계값) 변화에 대해 연속적이며, 급격한 변동이 없음을 보인다.
응용 사례로는 (a) 이진 이미지 집합을 구조화하는데, 각 이미지가 픽셀 기반 유사도 행렬을 통해 비교되고, 대표 예시가 이미지 군집의 중심 역할을 수행한다. 이를 통해 대규모 이미지 컬렉션을 소수의 핵심 이미지로 요약하면서도 원본 이미지와의 재구성 오류를 최소화한다. (b) 연구팀의 공동 저자 관계를 분석할 때, 저자 간 공동 논문 수를 가중치로 하는 그래프를 구성하고, Borda 점수를 통해 핵심 저자(대표 예시)를 도출한다. 이 핵심 저자들은 협업 네트워크의 연결 고리 역할을 하며, 팀 내 지식 흐름과 영향력을 시각화하는 데 유용하다.
실험 결과는 기존 군집화 기법(k‑means, DBSCAN)과 비교했을 때, 대표 예시 기반 네트워크가 군집 경계와 노이즈에 더 강인함을 보이며, 시각적 해석이 용이함을 입증한다. 또한 파라미터 민감도 분석을 통해 임계값 선택이 데이터 특성에 맞게 자동 조정될 수 있음을 시사한다. 전체적으로 이 프레임워크는 비지도 학습 상황에서 데이터의 핵심 구조를 추출하고, 이를 기반으로 네트워크 분석 및 요약 작업을 수행하는 데 효과적이다.