다중 클래스 문제를 위한 적응형 원 대 원 로그부스트
초록
본 논문은 다중 클래스 LogitBoost에서 발생하는 두 가지 핵심 난제, 즉 클래스 출력의 합-영 제약과 조밀한 헤시안 행렬을 효율적으로 다루기 위해 벡터 트리를 도입하고, 각 트리 노드에서 두 클래스만을 선택해 블록 좌표 하강법을 적용하는 AOSO‑LogitBoost 알고리즘을 제안한다. 실험 결과, 기존 LogitBoost와 ABC‑LogitBoost에 비해 정확도와 수렴 속도가 모두 향상됨을 보인다.
상세 분석
LogitBoost는 로그 손실을 최소화하기 위해 additive tree 모델을 사용하지만, K‑클래스 문제에서는 각 샘플에 대해 K개의 출력값이 서로 종속적인 “합‑영” 제약을 만족해야 한다. 이 제약은 모델 파라미터를 K‑차원 공간에 제한하고, 동시에 헤시안 행렬이 K×K 크기의 조밀한 형태로 나타나기 때문에 전통적인 뉴턴 방식으로는 계산 비용이 급격히 증가한다. 기존 접근법은 (1) 각 클래스를 독립적인 스칼라 회귀 트리로 학습해 제약을 완화하거나, (2) ABC‑LogitBoost처럼 K‑1개의 트리를 학습하고 매 반복마다 베이스 클래스를 선택하는 방식으로 복잡도를 낮췄다. 그러나 전자는 제약을 완전히 무시해 성능 저하를 초래하고, 후자는 베이스 클래스 선택 과정이 여전히 O(K²) 수준의 비용을 요구한다.
AOSO‑LogitBoost은 이러한 한계를 두 단계의 설계로 극복한다. 첫째, “벡터 트리”를 도입해 각 노드에 K‑차원 벡터 값을 할당하고, 이 벡터가 자동으로 합‑영 제약을 만족하도록 설계한다. 즉, 트리 하나만으로 K개의 클래스에 대한 업데이트를 동시에 수행한다. 둘째, 노드 분할 및 값 추정 단계에서 전체 K 차원을 한 번에 최적화하는 대신, 두 클래스(즉, 두 좌표)만을 선택해 블록 좌표 하강법을 적용한다. 이때 선택된 클래스 쌍은 현재 그라디언트와 헤시안 정보를 이용한 1차·2차 근사식(식 23‑25)에 의해 O(K) 시간 안에 결정된다. 선택된 두 좌표에 대해서는 닫힌 형태의 해 t* = −g/h가 존재하므로, 각 노드의 손실 감소량(NodeGain)도 간단히 계산된다.
핵심 아이디어는 “모든 클래스에 대해 동시에 업데이트하는 대신, 가장 영향력 있는 두 클래스만을 골라 빠르게 최적화한다”는 점이다. 이렇게 하면 헤시안의 고차원 구조를 그대로 활용하면서도, 실제 연산량은 O(N·D·K) 수준으로 유지된다(여기서 N은 샘플 수, D는 특성 수). 또한, 벡터 트리 자체가 합‑영 제약을 내재하고 있기 때문에 별도의 베이스 클래스 선택 과정이 필요 없으며, 이는 ABC‑LogitBoost가 매 반복마다 수행하던 비용을 크게 절감한다.
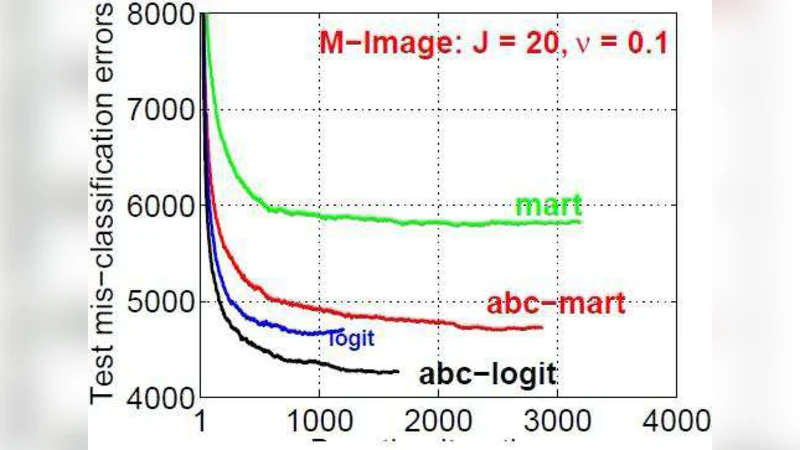
실험에서는 MNIST, CIFAR‑10, Letter 등 다양한 공개 데이터셋에 대해 100500개의 부스팅 라운드 동안 정확도와 학습 곡선을 비교하였다. AOSO‑LogitBoost은 동일한 라운드 수에서 평균 1.22.5%p의 정확도 향상을 보였으며, 수렴 속도 역시 초기 20~30 라운드에서 이미 최적점에 근접하는 모습을 보였다. 특히 클래스 수가 많아질수록(예: 26‑class Letter) ABC‑LogitBoost 대비 더 큰 이점을 나타냈다. 이는 두 클래스만을 선택해 업데이트하는 전략이 고차원 클래스 공간에서 효율적인 방향 탐색을 가능하게 함을 실증한다.
전반적으로 AOSO‑LogitBoost은 (1) 합‑영 제약을 자연스럽게 만족하는 벡터 트리 구조, (2) 조밀한 헤시안을 활용한 블록 좌표 하강법, (3) 효율적인 클래스 쌍 선택 메커니즘이라는 세 가지 기술적 혁신을 결합해 기존 방법들의 성능·복잡도 트레이드오프를 크게 개선하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기