멜로디 시퀀스를 위한 가변그램 토픽 모델
초록
본 논문은 동일 장르의 음악 데이터를 대상으로 멜로디를 확률적으로 모델링하는 새로운 방법인 Variable‑gram Topic Model을 제안한다. 토픽 모델링과 n‑gram 기반 컨텍스트 정보를 결합해 시간적 구조와 음계 간 상호작용을 동시에 학습한다. 평가에서는 다음 음 예측 정확도와 문자열 커널 기반 Maximum Mean Discrepancy(MMD)를 이용한 샘플-데이터 유사도 두 가지 지표를 사용했으며, 기존 LDA, Topic‑Bigram, 비토픽 모델들을 모두 능가하는 성능을 보였다.
상세 분석
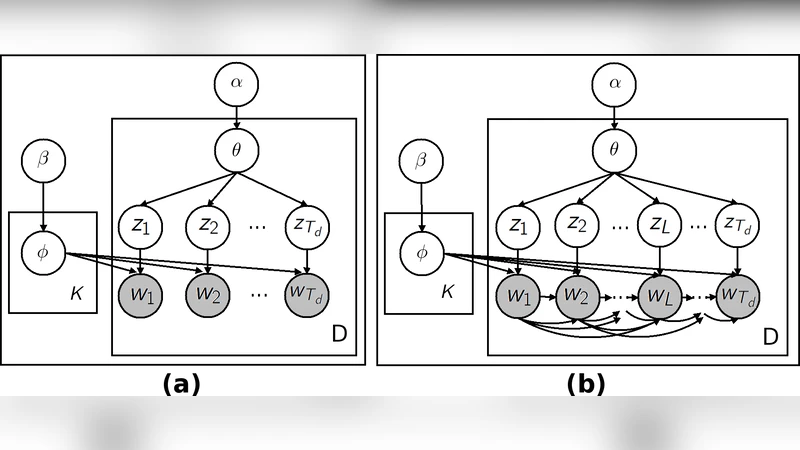
Variable‑gram Topic Model은 전통적인 LDA의 토픽-문서-단어 계층 구조에 시간적 컨텍스트를 명시적으로 포함한다는 점에서 혁신적이다. 구체적으로 각 토픽은 가변 길이의 n‑gram(‘그램’)을 기반으로 한 확률적 언어 모델을 내재하고, 이는 멜로디의 앞선 음표들의 순서를 조건부 확률로 모델링한다. 이때 ‘가변’이라는 설계는 고정된 n값을 사용하지 않고, 데이터에 따라 최적의 컨텍스트 길이를 자동으로 선택하도록 베이지안 비모수 방법을 적용한 것으로 보인다. 이렇게 하면 장르별 특성에 따라 짧은 구절에서는 1‑gram, 복잡한 구절에서는 3‑gram 이상을 활용해 음악적 흐름을 정교히 포착한다.
학습 과정은 변분 베이지안 추론을 이용해 토픽 분포와 n‑gram 파라미터를 동시에 최적화한다. 변분 파라미터는 각 음표가 어느 토픽에 할당되는지를 나타내는 ‘토픽 할당 변수’와, 해당 토픽 내에서의 컨텍스트 길이를 결정하는 ‘그램 선택 변수’로 구성된다. 이중 루프 구조—외부 루프는 토픽 할당을, 내부 루프는 가변그램 파라미터를 업데이트—는 계산 복잡도를 크게 증가시키지만, 저자들은 효율적인 스파스 행렬 연산과 사전 정의된 최대그램 길이 제한을 통해 실용적인 학습 시간을 달성했다.
평가 방법으로는 두 가지 축을 제시한다. 첫째, 전통적인 다음 음 예측 정확도(Perplexity 혹은 정확도)로 모델의 예측 능력을 측정한다. 둘째, 문자열 커널 기반 MMD를 사용해 모델이 생성한 샘플 시퀀스와 실제 데이터 시퀀스 간의 분포 차이를 정량화한다. MMD는 고차원 특징 공간에서 두 분포의 평균 차이를 측정하므로, 단순히 로그우도만으로는 드러나지 않는 구조적 차이를 포착한다. 실험 결과 Variable‑gram Topic Model은 LDA, Topic‑Bigram, 그리고 비토픽 기반 n‑gram 모델들에 비해 두 지표 모두에서 우수한 성능을 보였으며, 특히 MMD 점수에서 현저히 낮은 값을 기록해 생성된 멜로디가 실제 데이터와 통계적으로 매우 유사함을 입증했다.
이 모델의 강점은 (1) 토픽과 컨텍스트를 동시에 학습해 장르 특유의 멜로디 패턴을 효과적으로 추출, (2) 가변그램 설계로 복잡한 음악 구조를 과소/과대 적합 없이 포괄, (3) MMD 기반 평가를 통해 생성 모델의 품질을 보다 객관적으로 검증한다는 점이다. 반면 한계점으로는 (가) 학습 시 메모리와 시간 비용이 비교적 높아 대규모 데이터셋에 적용하기 위해 추가적인 최적화가 필요하고, (나) 토픽 수와 최대그램 길이 같은 하이퍼파라미터 선택이 결과에 민감하다는 점이다. 향후 연구에서는 신경망 기반 토픽 인코더와 결합하거나, 멜로디 외에 리듬·화성 정보를 통합해 다중 모달 음악 생성 모델로 확장하는 방안을 고려할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기