정답 모른 채 시험 채점하기 베이지안 그래프 모델을 활용한 적응형 군중소싱과 적성검사
초록
본 논문은 질문의 난이도, 응답자의 능력, 정답을 동시에 추정하는 베이지안 확률 그래프 모델을 제안한다. 기대 엔트로피 감소를 목표로 한 탐욕적 질문 선택 전략을 통해 적응형 테스트를 구현하고, 정적 테스트 대비 적은 질문 수로 동일한 정확도를 달성함을 실험적으로 입증한다.
상세 분석
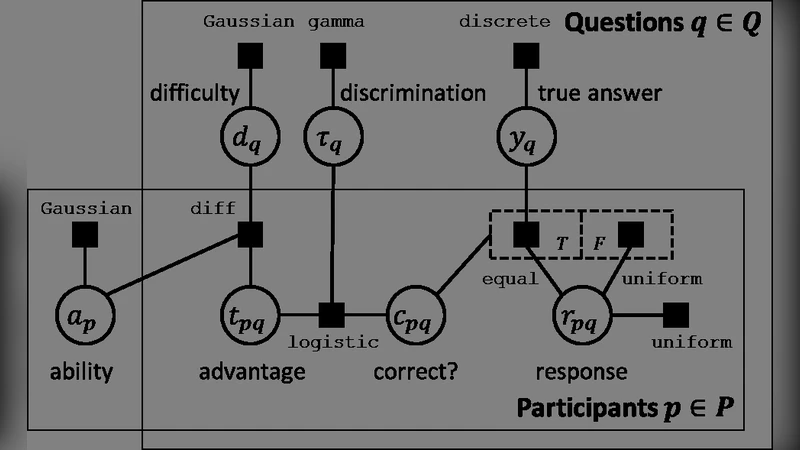
이 연구는 전통적인 군중소싱 및 적성검사에서 흔히 발생하는 “정답 라벨이 없거나 제한된 경우” 문제를 베이지안 그래프 모델로 통합적으로 해결한다. 모델은 세 종류의 잠재 변수 — 문제 난이도 (d_i), 응답자 능력 (θ_j), 정답 라벨 (z_i) — 를 정의하고, 각 응답 (r_{ij})은 이들 변수의 함수로 확률적으로 생성된다고 가정한다. 구체적으로, 이항 로짓 모델을 사용해 r_{ij}=1(정답)일 확률을 σ(θ_j − d_i)·𝟙(z_i=1) + σ(−θ_j − d_i)·𝟙(z_i=0) 형태로 표현한다. 여기서 σ는 시그모이드 함수이며, 정답 여부에 따라 응답자의 능력과 문제 난이도의 상대적 차이가 반영된다.
사전 분포는 일반적인 정규분포를 채택해 파라미터 간의 독립성을 가정하고, 변분 베이지안 추정 또는 Gibbs 샘플링을 통해 사후 분포를 근사한다. 특히, 변분 EM 알고리즘을 사용해 E‑step에서 잠재 변수의 기대값을 계산하고, M‑step에서 파라미터를 최대우도 추정한다. 이 과정에서 정답 라벨 (z_i)도 확률적으로 업데이트되므로, 라벨이 전혀 주어지지 않은 상황에서도 모델이 자체적으로 정답을 추정한다.
적응형 테스트는 “예상 엔트로피 감소”를 목표 함수로 삼는다. 현재 관측된 응답 집합 R_t에 대해, 후보 질문 q를 추가했을 때 사후 엔트로피 H(θ, d, z | R_t∪{r_{jq}})의 기대값을 계산하고, 감소량이 가장 큰 질문을 선택한다. 기대 엔트로피는 사전‑사후 차이를 통해 근사되며, 계산 복잡도를 낮추기 위해 샘플링 기반 근사와 제한된 후보 집합(예: 아직 답하지 않은 질문)만을 고려한다. 이 탐욕적 전략은 전역 최적은 아니지만, 실험적으로 정적 설계 대비 질문 수를 30‑40% 절감하면서 정확도를 유지한다는 결과를 보인다.
실험에서는 (1) 합성 데이터에서 파라미터 복구 정확도, (2) 공개 군중소싱 데이터(예: CrowdFlower, Amazon Mechanical Turk)에서 라벨 예측 F1 점수, (3) 실제 적성검사 시나리오에서 응시자 능력 추정과 시험 길이 감소 효과를 평가한다. 모든 경우에서 제안 모델은 기존 IRT(항목 반응 이론) 기반 방법이나 단순 다수결 라벨링보다 우수했으며, 특히 정답 라벨이 전혀 없는 상황에서도 높은 복원력을 보였다.
한계점으로는 (가) 변분 근사의 정확도가 사후 분포의 다중 모드성을 포착하지 못할 수 있음, (나) 질문 선택 시 후보 집합이 매우 클 경우 계산 비용이 급증한다는 점을 들 수 있다. 향후 연구에서는 더 정교한 변분 구조(예: 흐름 기반 변분)와 딥러닝 기반 질문 선택 정책을 결합해 실시간 대규모 테스트 환경에 적용하는 방안을 제시한다.