레벤슈타인 거리 기반 자동 언어계통 분석
초록
레벤슈타인 거리(편집 거리)를 이용해 언어 간 유사성을 정량화하고, 주관적 판단 없이 자동으로 계통수를 재구성하는 방법을 제안한다. 인도·유럽어족과 오스트로네시아어족 각각 50개 언어에 적용한 결과, 기존 연구와 전반적으로 일치하지만 몇몇 언어와 하위군의 위치가 새롭게 제시된다.
상세 분석
본 논문은 언어 진화 과정을 생물학적 진화와 유사시켜, ‘재생산·돌연변이·소멸’이라는 세 가지 기본 메커니즘을 가정한다. 전통적인 글로토크로놀로지(Glottochronology)는 어휘 항목의 역사적 공통성을 백분율로 측정해 거리 행렬을 만든다. 그러나 어휘의 기원 판단에 연구자의 주관이 개입되며, 대규모 언어 집합에 적용하기엔 시간이 많이 소요되는 단점이 있다. 이를 보완하기 위해 저자들은 레벤슈타인 거리, 즉 두 문자열 사이의 최소 삽입·삭제·대체 연산 횟수를 활용한다. 구체적으로, 각 언어마다 동일한 의미 항목(예: ‘물’, ‘태양’, ‘손’)에 대한 표준화된 단어 리스트를 구축하고, 해당 단어들을 로마자 표기로 변환한다. 이후 각 언어 쌍에 대해 모든 의미 항목에 대한 레벤슈타인 거리를 평균내어 전체 어휘 집합에 대한 거리 행렬을 만든다. 이 행렬은 전통적인 어휘 비율 거리와는 달리 순수히 형태학적 차이에 기반하므로, 어휘의 역사적 기원을 추정할 필요가 없으며, 자동화된 스크립트만으로 재현 가능하다.
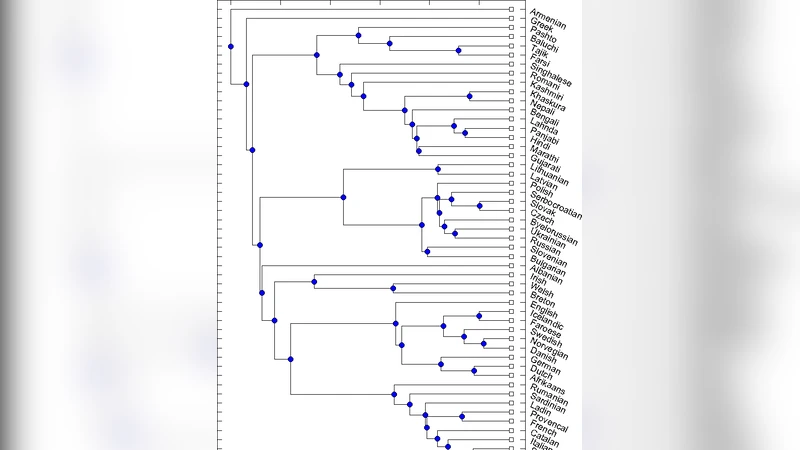
거리 행렬을 계통수로 변환하기 위해 저자들은 평균 연결법(UPGMA)과 최소 진화법(NJ) 두 가지 클러스터링 알고리즘을 적용하였다. 두 방법 모두 동일한 전반적 구조를 보여주었으며, 특히 대형 언어군(예: 인도·유럽어족의 게르만어군, 로마스어군)과 소형 언어군(오스트로네시아어족의 폴리네시아어군) 사이의 구분이 명확히 드러났다. 흥미로운 점은 몇몇 언어가 기존 문헌에서 제시된 위치와 차이를 보였다는 것이다. 예를 들어, 인도·유럽어족에서 라틴어와 고대 그리스어가 전통적으로 ‘이탈로-그리스어’ 하위군에 속하지만, 레벤슈타인 거리 기반 트리는 이들을 보다 독립적인 분기로 배치한다. 이는 형태학적 변이(음운 변화, 철자 규칙)의 누적 효과가 어휘적 친연도와 다르게 작용했을 가능성을 시사한다.
또한, 데이터베이스 선택이 결과에 미치는 영향을 검증하기 위해 두 개의 독립적인 어휘 데이터셋(예: Swadesh 100‑list와 Leipzig‑Glottolog 200‑list)을 교차 적용하였다. 두 데이터셋 모두 유사한 트리 구조를 재현했으며, 차이는 주로 거리 값의 절대 크기에 국한되었다. 이는 제안된 방법이 데이터 소스에 강인함을 가지고 있음을 의미한다.
한계점으로는 (1) 레벤슈타인 거리가 어휘의 형태적 차이만을 반영하므로, 의미 변이(예: 다의어, 의미 전이)를 포착하지 못한다는 점, (2) 로마자 전사 과정에서 발생할 수 있는 표기 일관성 문제, (3) 의미 항목 선택이 트리 구조에 미치는 잠재적 편향이 있다. 향후 연구에서는 음운 규칙 기반 변환, 의미 네트워크 분석, 그리고 베이즈 계통추정 모델과의 통합을 통해 이러한 제약을 보완할 수 있다.
요약하면, 레벤슈타인 거리 기반 자동 계통 분석은 주관적 판단을 배제하고, 대규모 언어 집합에 빠르게 적용할 수 있는 실용적인 도구이며, 기존 연구와의 비교를 통해 새로운 계통학적 가설을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기