미국 도·군 간 이동 흐름의 이중표준화와 계층적 군집화 시각화
초록
본 논문은 1995‑2000년 미국 3,107개 카운티 간 인구 이동 데이터를 이중표준화(모든 행·열 합을 1로 맞춤)한 뒤, 부지배 고유벡터와 강성 성분 계층적 군집화를 이용해 행·열 순서를 재배열한 매트릭스 플롯을 제시한다. 재배열된 행렬에서 ‘코스모폴리탄’(Sunbelt)과 ‘블랙벨트’(Deep South) 지역 간 이동 패턴의 차이가 시각적으로 드러난다.
상세 분석
이 연구는 미국 인구조사 데이터를 기반으로 3,107 × 3,107 규모의 비대칭 이동 행렬을 구축하고, 먼저 대각선(자체 이동)을 0으로 설정한 뒤 행·열 합을 반복 비례 조정(iterative proportional fitting)하여 전 행렬을 이중표준화(bistochastic)한다. 이 과정은 각 카운티의 절대 인구 규모 차이를 제거하고, 순수히 ‘상호작용 비율’(relative odds)만을 보존한다는 점에서 중요한 전처리 단계이다.
이중표준화된 행렬의 주 고유값은 1이며, 대응 고유벡터는 균등 벡터이므로 의미가 없다. 대신 저자들은 실수 부지배 고유값 0.906253에 대응하는 좌·우 고유벡터(입·출 이동 패턴)를 사용해 카운티 순서를 재배열하였다. 좌 고유벡터 기반 재배열(Fig. 3)과 우 고유벡터 기반 재배열(Fig. 4)은 각각 인구 유입·유출 강도를 반영한다. 두 플롯 모두 대각선 클러스터링이 크게 약화되고, 전체가 두 개의 거대한 블록으로 나뉘는 구조가 드러난다.
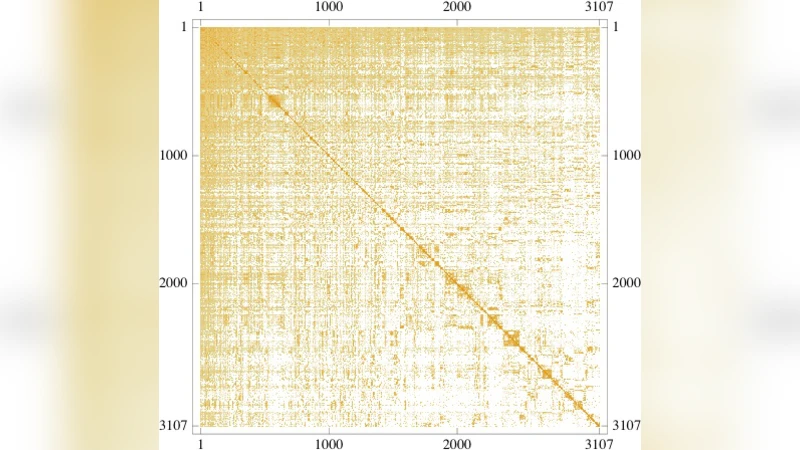
다음 단계에서는 강성 성분(strong component) 기반 계층적 군집화(단일 연결법의 방향 그래프 버전)를 적용해 3,107개의 카운티를 38페이지에 걸친 덴드로그램으로 정렬하였다. 이 순서에 따라 행렬을 재배열한 결과(Fig. 5)는 ‘코스모폴리탄’ 군집(플로리다, 남부 캘리포니아, 텍사스 등)과 ‘블랙벨트’ 군집(미시시피·앨라배마·조지아 등) 사이의 명확한 구분을 보여준다. 특히, 초기 12개 카운티는 전국 전역으로 인구 흐름을 주도하는 허브 역할을 하며, 마지막 35개 카운티는 지역 내에 머무르는 경향이 강해 ‘프로빈셜’ 특성을 나타낸다.
저자는 또한 Mathematica의 DirectAgglomerate 명령을 이용해 대칭 가정 하에 다시 군집화를 수행한 결과(Fig. 8, 9)를 제시한다. 전치 행렬에 적용했을 때 군집 구조가 약간 변하지만, 전체적인 코스모폴리탄‑프로빈셜 이분법은 유지된다.
통계적 검증으로는 다양한 순서 간 피어슨 상관계수를 계산했으며, 0.0353 이상의 절대값은 95 % 수준에서 유의함을 확인했다. 특히 행정적 알파벳 순서와 비교했을 때, 고유벡터·군집화 기반 순서는 거의 무상관에 가까워 데이터 자체가 내포한 구조적 패턴을 효과적으로 드러낸다.
이 연구는 이동 흐름 데이터에 이중표준화와 고유벡터·강성 성분 군집화를 결합함으로써, 전통적인 행정 구역 기반 시각화가 놓치는 잠재적 ‘허브‑주변’ 구조를 밝혀낸다. 저자는 이러한 방법론이 학술 인용 네트워크(Science, Nature, PNAS 등)와 같은 다른 트랜잭션 흐름 데이터에도 적용 가능함을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기